
Datagedreven
werken aan
veiligheid.
Datagedreven werken aan veiligheid
In elke organisatie maken mensen besluiten op basis van informatie. Datagedreven werken neemt dat als uitgangspunt en breidt het uit. Door grote hoeveelheden data en informatie op slimme manieren te ontsluiten en te analyseren, kun je nauwkeuriger en efficiënter besluiten nemen.
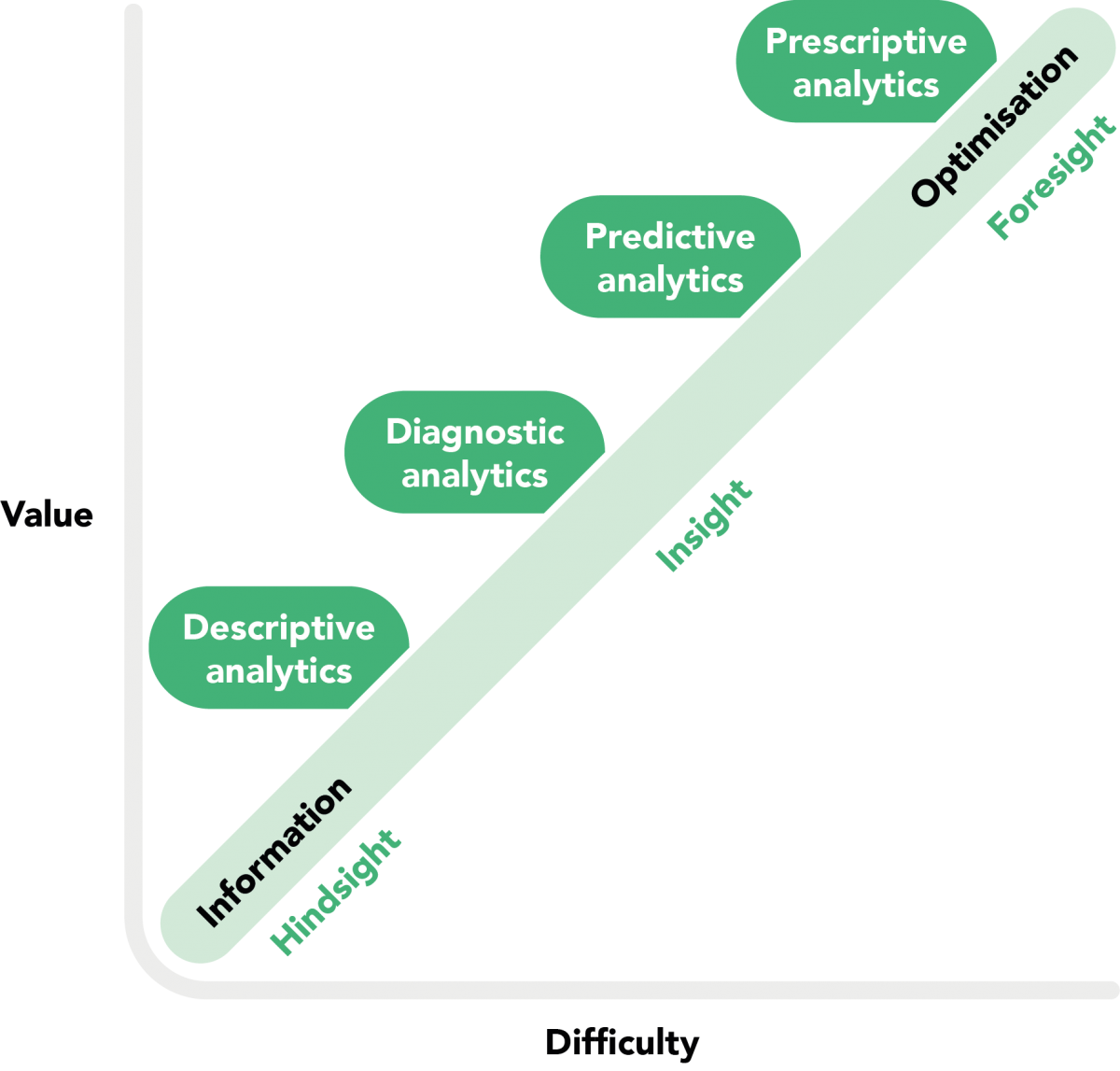
Aan het begin van datagedreven werken staat het beschikbaar hebben of krijgen van ‘schone’ gestructureerde data. Zie het als een stevig fundament dat op orde moet zijn, voordat een huis kan worden gebouwd. Als het fundament op orde is beginnen organisaties vaak met beschrijvende analyses, ’descriptive analytics’. Bijvoorbeeld in de vorm van dashboards om te kijken naar historische data en daarmee inzicht krijgen in het (nabije) verleden. Eén stap verder is het uitvoeren van diagnostische analyses, ‘diagnostic analytics’: waarom is iets gebeurd? Hier gaat het erom met statistische inferentie relaties en patronen te ontdekken in de data, zodat je een probleem beter kunt doorgronden.
Als je op basis van het verleden iets wil zeggen over de toekomst, hebben wij het over voorspellende analyses, ‘predictive analytics’. Denk aan het voorspellen van het aantal aanvragen voor rechtsbijstand in de toekomst, of het aantal incidenten in een uitgaansgebied op een bepaald moment. De laatste stap zijn voorschrijvende analyses: een algoritme die je op basis van een voorspelling vertelt wat je het beste kunt doen. Wij zien dat slechts enkele organisaties al systematisch werken met voorspellende en voorschrijvende analyses, ‘prescriptive analytics’. En dat is ook logisch. Waarom de toekomst voorspellen als je nog niet weet wat in het verleden heeft plaatsgevonden en waarom iets gebeurde?
Use Case 1
Criminele netwerken in één overzicht
Van april tot en met juni kon de Nationale Politie door versleutelingsservice EncroChat te hacken, meelezen met berichten van duizenden criminelen. Een goudmijn, maar wel een goudmijn die overweldigt. Hoe analyseer je, met beperkte mankracht en onder hoge tijdsdruk, 20 miljoen tekstberichten van criminelen? In 20 miljoen berichten staat te veel informatie om alleen door mensen geanalyseerd te worden. Naast de tekstberichten is ook de metadata een schat van informatie. Op basis van de metadata kun je zien wie met elkaar in contact staan. Wanneer je dat combineert met het weergeven van tijdspaden en geografische data kun je verbanden gaan leggen. Bijvoorbeeld op welke dagen welke bendes waar het meest actief zijn. Of hoe de organisatie van criminele groeperingen verandert over tijd. Het in een dashboard visueel weergeven van criminele netwerken en mogelijke relaties, creëert overzicht.
Onze ervaring leert dat wanneer je data overzichtelijk weergeeft, dit helpt om menselijke aannames te testen. Een ervaren rechercheur kan bijvoorbeeld aannames meenemen uit voorgaande zaken, die misschien in het EncroChat onderzoek niet opgaan. Ook helpt het om knelpunten bloot te leggen. Door overzicht te creëren zie je sneller welke cruciale informatie ontbreekt. Misschien geen goed nieuws, maar als je weet welke puzzelstukjes missen, kun je daar naar handelen.
Vaak is overzicht creëren door middel van dashboards het begin van datagedreven werken. Zo ook in het EncroChat onderzoek. Om meer complexe verbanden te vinden is soms een stapje extra nodig. Met data science technieken als Natural Language Processing (NLP) kun je de berichten classificeren op basis van onderwerp of zaak. Ook kun je een model trainen dat cruciale informatie uit tekstberichten onttrekt, of welke berichten met spoed door rechercheurs moeten worden opgepakt. In de volgende twee use-cases komen meer van dit soort technieken aan bod.
Use Case 2
Inzicht door woninginbraken te modelleren
Waarom kiest een inbreker ervoor om de ene woning te betreden en niet de andere? Helaas kunnen we niet meekijken in het hoofd van een inbreker. Wel kunnen wij uit historische data afleiden wat een woning aantrekkelijk maakt.
Heeft bijvoorbeeld een hoekwoning meer kans op een inbraak dan een rijtjeshuis? En wat is het effect van het hebben van een balkon of tuin? Of hangt het meer af van de inwoners van een woning: lopen oude mensen meer risico dan twintigers? En wat is het effect van gezinsgrootte op de kans op een woninginbraak? En maakt het uit hoe gunstig de woning ten opzichte van uitvalswegen en treinstations ligt?
Misschien dat je één van bovenstaande vragen kunt beantwoorden met een paar kengetallen die je terugleest in een rapportage van de politie. Maar hoe beantwoord je al deze vragen in samenhang met elkaar? Wij mensen vinden het lastig om meer dan drie factoren tegelijkertijd mee te nemen, computers doen dat moeiteloos!
Door de data te modelleren – een soort wiskundige formule over de werkelijkheid te leggen – kun je te weten komen wat risicofactoren zijn, voor wie en in welke wijk. In dit voorbeeld zou je bijvoorbeeld gebruik kunnen maken van een multilevel logistische regressie. De uitkomsten van dit model kun je goed interpreteren. Het model houdt er rekening mee dat woningen in wijken liggen, die onderling van elkaar kunnen verschillen. In ons vakjargon: dit model houdt rekening met de hiërarchische structuur van de data.
En het goede nieuws is: veel gemeenten hebben de data voor zo’n analyse al in huis. Denk aan de Basisregistratie Personen (BRP) en de Basisregistratie Adressen en Gebouwen (BAG). Via het CBS kan je deze gegevens verrijken met demografische informatie over de wijk of het betreffende postcodegebied. De politie weet waar woninginbraken plaatsvonden. Via gegevens over de hondenbelasting zou je zelfs het effect van een (waak)hond kunnen meenemen in je analyse. Hoewel je natuurlijk niet weet of er achter de voordeur een pitbull of een chihuahua aan het grommen is.
In één overzicht zie je bijvoorbeeld of een appartement meer risico loopt op een woninginbraak dan een vrijstaand huis en of dat verschil significant is. Of je woninginbraken kunt verklaren door te kijken naar eigenschappen van de woning, of juist van haar bewoners. Zogenaamde interactie-effecten kan je ook aan het licht brengen: wanneer het effect van een factor beïnvloed wordt door een ándere factor. Bijvoorbeeld of een tuin het risico op woninginbraak verhoogt en of dit risico groter is voor 65-plussers dan voor starters.
Er zijn dus meerdere mogelijkheden om je veiligheidsbeleid heel gericht aan te scherpen. Maar je kunt ook de projecten van afgelopen jaren beoordelen. Weten ze binnen jouw afdeling waar bijvoorbeeld is geïnvesteerd in het verbeteren van het hang- en sluitwerk met een Politiekeurmerk Veilig Wonen? Is er informatie over in welke straten de BOA’s een extra ronde lopen? Waar de ‘Attentie Buurtpreventie’-borden zijn geplaatst, of flyers voor het Donkere Dagen Offensief in de bus zijn gedaan? Zonde om dit niet mee te nemen in de analyses: zo kom je te weten welke elementen in je aanpak het verschil hebben gemaakt en voor wie.
Ook hier helpt data je door inzicht te geven in wat werkt en wat niet. Met die inzichten kun je de aanpak aanscherpen en de middelen inzetten op die plekken waar je het verschil weet te maken.
Use Case 3
Voorspellen van hennepkwekerijen
Voorspellende analyses vinden opdrachtgevers vaak één van de meest spannende analyses. En dat begrijpen wij wel. Neemt de computer straks onze beslissingen over? Komt onze veiligheid in de handen te liggen van computermodellen? Nee. Wel zien wij dat het primaire proces steeds beter wordt ondersteund door voorspellende analyses. Bijvoorbeeld bij het opsporen van hennepkwekerijen.
Deze kwekerijen in woningen vormen om meerdere redenen een probleem: verhoogd brandgevaar, het illegaal aftappen van stroom en het ondermijnende effect dat uitgaat van kwekerijen in de buurt: de buurjongens die toppen knippen, omdat dat een lucratievere bijbaan is dan werken bij de supermarkt. Bovendien is de meldingsbereidheid vaak laag. Wat te doen als de melding niet komt? Wachten op de sneeuwval die een warmte-installatie op zolder verraadt?
Er is veel data beschikbaar over bewoners en woningen. Door machine learning algoritmes toe te passen op de data van bewoners en woningen, kunnen lineaire en niet-lineaire verbanden worden ontdekt die een voorspellende waarde hebben. Daarmee kun je een risico-inschatting maken voor een combinatie van huis en inwoner. Omdat criminelen steeds creatiever worden (verhuizingen of objecten veranderen) is het verstandig zo’n analyse elke drie tot zes maanden opnieuw uit te voeren. Door uitvoerig te documenteren en goed leesbare code te schrijven, kan dat bijna met één druk op de knop.
Het is ontzettend belangrijk van begin tot eind zorgvuldig te werk te gaan om onbedoelde neveneffecten te vermijden. Bijvoorbeeld door een scan uit te voeren naar de kwaliteit van de data. Een voorspellend model is zo goed als de data waarmee het wordt gevoed: garbage in betekent garbage out. Variabelen die een stigmatiserende werking kunnen hebben, moeten worden geïdentificeerd en weggelaten uit de analyse. En partners in de veiligheidsketen dienen – na een training over hoe je de output van een voorspelmodel interpreteert – om tafel te gaan om de output van het voorspelmodel te bespreken. Dan zijn het de professionals en niet de computers die een beslissing nemen.
Tenslotte wil je voorkomen dat je enkel en alleen achter de usual suspects aangaat. Er zijn type hennepkwekerijen die niet of nauwelijks worden opgerold, bijvoorbeeld omdat de criminelen inventiever zijn of op een andere manier atypisch zijn voor de groep. Het is niet waarschijnlijk dat je die opspoort met een voorspelmodel dat is getraind om typische hennepkwekerijen te signaleren. Om toch zicht te krijgen op de unusual suspects, zou je op dezelfde data een outlier detection model kunnen trainen. Zo’n model gaat op zoek naar de datapunten die het meest afwijken van het gemiddelde. Zo kun je toch zicht proberen te krijgen op hennepkwekerijen die nog niet in beeld zijn.
Klinkt goed! Waar begin ik?
Zodra je je ogen opent voor de kansen die datagedreven werken met zich meebrengen, begint de uitdaging. Waar te beginnen? Welke use-cases zijn voor ons van toepassing? Hoe kunnen we het integreren in ons huidige IT-landschap en hoe zorg je voor intern draagvlak om toepassingen succesvol te implementeren?

