
DE TECHNIEK ACHTER DE
NEW ENGLAND IPA.
Een bier maken met AI, leuk idee! Maar hoe gaan we dit realiseren? Er schoten direct tientallen mogelijkheden en ideeën door het hoofd. Maar welke is het meest haalbaar? Dit hangt af van de gebruiker die aan de slag gaat met de uiteindelijke output van het model. In deze blog zullen wij verder ingaan op de techniek en modellen die zijn toegepast tijdens het proces en antwoord geven op de vraag: hoe is dit data gedreven bier technisch tot stand gekomen?
In de voorgaande blog over webscraping wordt ingegaan op de methode van het verzamelen van data, dat geldt als input voor het proces. Deze data bestaat uit online reviews, afkomstig van diverse online platformen. Features hiervoor zijn onder andere waardering, reacties, bierstijl en alcoholpercentage. Om tot een datagedreven bier te komen hebben we kenmerken nodig van verschillende bieren in de dataset aangevuld met een ‘predictor’. Dit laatste is in ons geval een weging van de gemiddelde review score met het aantal reviews van een bier. Het doel is om een model te trainen, waarbij we een optimale weging van score en aantal reviews zoeken, met de kenmerken en smaken van het bier als features.
Wij zijn opzoek naar de optimale kenmerken voor een bier van een specifieke bierstijl. Sommige informatie is vrijwel kant-en-klaar beschikbaar als feature. Denk hierbij aan het alcoholpercentage, het beoordelingscijfer of de bierstijl. Andere zaken, bijvoorbeeld de smaken die je proeft, zijn niet direct voor handen. Welke combinatie van smaken doen het goed voor een specifieke bierstijl? Een frisse New England IPA met passievrucht of toch een NEIPA waarin zoetigheid en mango naar voren komen? Om van deze vele comments soep te maken in de vorm van verschillende features, gingen wij aan de slag met Natural Language Processing (NLP). Het beoogde doel is om voor elk bier van Brouwerij het Uiltje, zoals Bird of Prey en Dikke Lul 3 Bier, een volgende set met een X aantal smaak-features te krijgen.

We willen uit deze ongestructureerde en grote hoeveelheid data bepaalde informatie halen. Het gaat om bepaalde bierkenmerken waarnaar verwezen wordt in de reviews van het bier. Dit betekent dat veel informatie in een comment waardeloos gaat zijn. Bijvoorbeeld in de review waarin iemand het bier GoodFeathers van Uiltje een 8/10 geeft:
“Uiltje’s Brut IPA is wat zoet (proef iets van appel), droog, meer champagne-achtig dan bier. Precies zoals een brut IPA hoort te zijn.”
In deze comment staan woorden zoals ‘Uiltje’, ‘IPA’, ‘bier’, ‘brut’ en ‘proef’. Woorden waar wij niet in geïnteresseerd zijn. Dergelijke informatie zegt in dit geval niets over de ervaring van de consument. Echter, woorden als ‘zoet’, ‘appel’, ‘droog’ en ‘champagne’ zijn wél interessant. Aan de hand van de beoordelingsscore in de review kunnen hier waardes aan worden gehangen.
Om enkel de gewenste informatie uit een comment te extraheren, moeten een aantal ingrepen op deze data worden uitgevoerd. Hierbij wordt gebruik gemaakt van een aantal Python packages, namelijk: nltk, scikit-learn, pandas en numpy.
Allereerst moeten de comments die gebruikt worden in de vorm van strings worden aangepast. Hierdoor worden alle irrelevante woorden, ook wel stopwoorden genoemd, eruit gefilterd. De package NLTK heeft standaard lijsten hiervoor beschikbaar in verschillende talen. Wij gebruiken de Nederlandse en Engelse lijsten en vullen deze aan met een aantal casus specifieke stopwoorden zoals ‘bier’, ‘Uiltje’, ‘IPA’, ‘Craft’, etc. In Python ziet dat er als volgt uit:

Hiermee kan een lijst met woorden worden gemaakt waar de stopwoorden zijn uitgefilterd. Echter, dit zijn nog geen kenmerken. Sommige woorden zullen bijvoorbeeld nog erg op elkaar lijken, denk aan ‘hop’ & ‘hoppy’. Voor diegene met NLP-ervaring zal de oplossing logisch zijn, ‘Stemming’. Stemming is het terugbrengen van woorden naar de stam, bijvoorbeeld ‘play’ maken van ‘playing’ of ‘zoet’ maken van ‘zoetig’. Daarnaast zullen sommige woorden hoofdletters bevatten, andere niet, zullen er stukken tekst zijn met niet enkel alfabetische tekens, etc. Er moet dus nog meer ‘preprocessing’ plaatsvinden op de teksten uit de comments. Dit doen we met de volgende code, gebruik makende van de eerdere gedefinieerde functie:

Nu zijn de review comments gefilterd. Wat er nu nog te doen staat is de meest genoemde kenmerken per bier te identificeren. Anders gezegd: de woorden moeten worden gerankt. We geven de woorden hiermee een relatieve graad waarin dit woord ‘belangrijk’ is. Hiervoor gebruiken wij TF-IDF (Term Frequency – Inverse Data Frequency). Een hele mond vol, maar wat houdt dit in? Term Frequency (TF) is het aantal keer dat een specifiek woord voorkomt ten opzichte van het totaal aantal woorden. Inverse Data Frequency (IDF) is het logaritme van – in dit geval – het aantal reviews gedeeld door het aantal reviews waarbij een specifiek woord wordt gebruikt. TF-IDF is vervolgens het product van beide.
Goed, na dit gedeelte theorie kunnen wij verder richting het data gedreven bier. Scikit-learn heeft gelukkig een aantal TF-IDF functies beschikbaar, hier maken wij dan ook gebruik van. Wij willen per bier een lijst met belangrijkste woorden uit comments bepalen. Om dit te realiseren maken wij drie functies: een functie die een ‘Bag of Words’ maakt en dit omzet in een TF-IDF representatie, een functie die de topwoorden bepaald voor een stuk tekst en één die de topwoorden bepaald voor een groep.

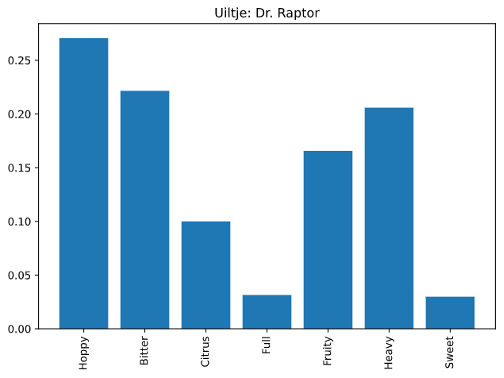
Deze functies kunnen worden gebruikt nadat de comments door de eerder gedefinieerde ‘preprocess’ functie zijn gehaald. Hiermee kunnen we – gegeven een Pandas dataframe met reviews – een lijst van dataframes teruggeven met de top TF-IDF woorden per bier. Bijvoorbeeld, voor het bier ‘Dr. Raptor’ van het Uiltje vinden we de volgende woorden als hoogst scorende TF-IDF woorden:
In code ziet dit er als volgt uit:

Hiermee zijn we er! Tenminste we hebben de meest betekenisvolle kenmerken per bier uit de comments weten te halen. Een optimaal bier is er nog niet. Deze kenmerken kunnen nu – samen met reeds bekende features als alcoholpercentage, bierstijl, IBU en beoordeling – als feature dienen in het vervolg van dit proces. Hierbij nemen we de TF-IDF woorden van elk bier op als feature, met de score als waarde. Wanneer een bier voor een bepaald woord geen noemenswaardige TF-IDF score heeft, krijgt die feature voor dat bier de waarde 0.

Dus wat nu? We gaan modeleren! Wat ons te doen staat is het bepalen van de smaakcombinatie welke het optimale bier moet gaan hebben. Dit wordt gedaan door de data te gebruiken in een ‘supervised regression model’, namelijk een random forest. Wederom maken wij hiervoor gebruik van een functie uit de Scikit-learn package, namelijk RandomForestRegressor. Deze functie wordt gebruikt in een eigen functie om de optimale smaakverhoudingen te bepalen en te plotten.

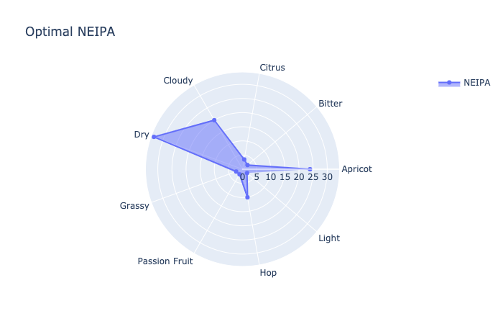
Dit model geeft de verhoudingen weer van de best mogelijke smaakcombinatie. Belangrijk hierbij is dat het om verhoudingen gaat. De hoogst scorende kenmerk moet niet overdadig aanwezig zijn. De combinatie en verhouding van de smaken is wat het optimaal maakt. Deze verhouding wordt doorgegeven aan Brouwerij het Uiltje als input voor het recept. Welke smaken dit zijn voor een New England IPA zie je hieronder.
Daarmee is het technische gedeelte compleet! Een data gedreven bier wat nu in de handen ligt van de brouwers. De komende periode gaan zij aan de slag om het bier zo goed mogelijk overeen te laten komen met de uitkomsten van de data. Ben je benieuwd naar het deze New England IPA? Houdt ons in de gaten voor updates over het productieproces!
