ARTIS datagedreven bezoekersfeedback
ARTIS, in hartje Amsterdam, is een plek waar dieren, planten, microben en sterren samenkomen. Een bezoek aan ARTIS is niet compleet zonder een kijkje bij de (zee)leeuwen, een hapje eten in het volledig vegetarische restaurant, en een bezoek aan het Groote Museum. Na een eerdere succesvolle samenwerking, waarin wij samen met ARTIS een chatbot hebben ontwikkeld, zijn de handen weer ineengeslagen voor een nieuw project. ?
Datagedreven bezoekersfeedback
DOEL
Jaarlijks geven duizenden bezoekers feedback via een enquête over ARTIS. ARTIS wil daar graag naar luisteren! Waar praten de bezoekers over? Welke onderwerpen vinden bezoekers belangrijk? Waar zijn ze enthousiast over en waar liggen de verbeterpunten? Het doorlezen van duizenden responses en hierbij op zoek gaan naar een gemene deler is zeer tijdrovend en arbeidsintensief. Aan ons de vraag, kan dit ook datagedreven?
RESULTAAT
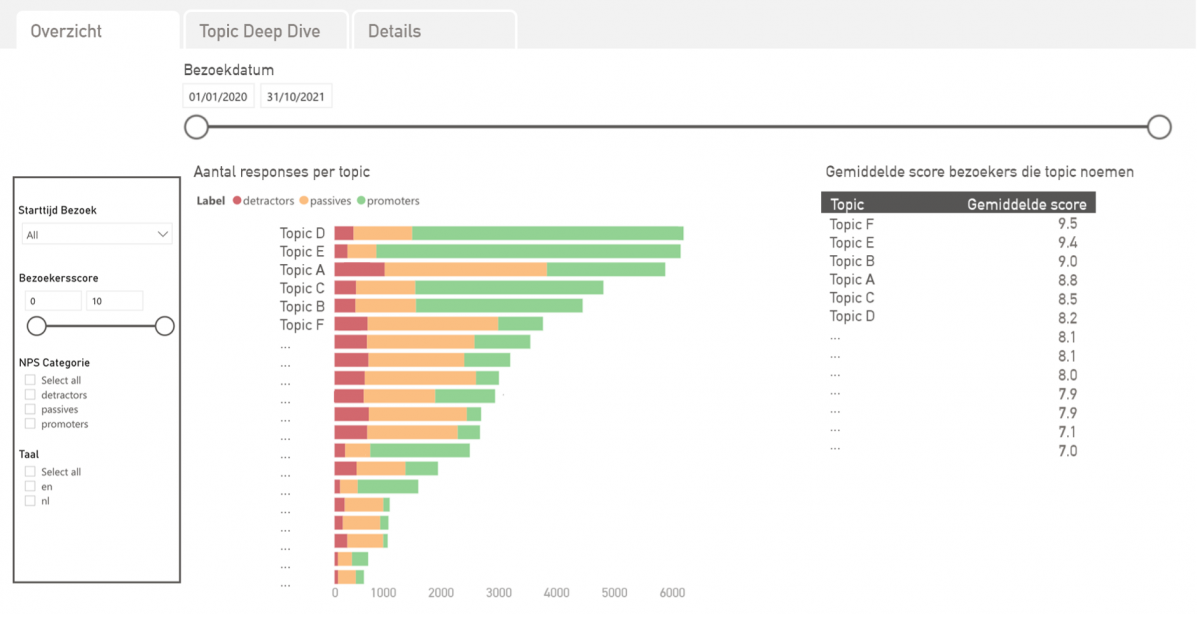
In het ‘Bezoekersfeedbackdashboard’ ziet ARTIS in één oogopslag welke onderwerpen het meest besproken worden. En kan ARTIS de gemiddelde score zien die een bezoeker aan het totale bezoek aan ARTIS geeft. Dit is gefilterd op genoemde onderwerpen (topics) in de gegeven feedback. Binnen het topic is een ‘deep dive’ mogelijk.
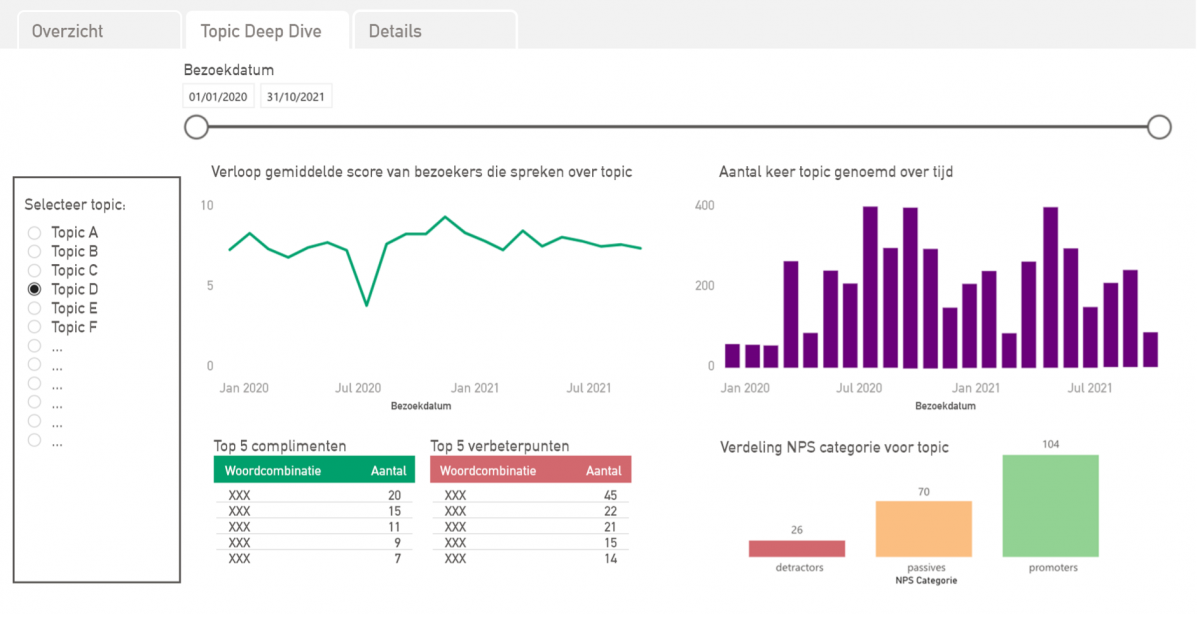
In de tab ‘Topic Deep Dive’ worden per onderwerp de algemene statistieken en de vaakst genoemde complimenten en verbeterpunten weergegeven. In de tab ‘Details’ kan ARTIS per onderwerp de bijbehorende responses terugvinden.
Neem als voorbeeld het topic ‘looproute en bewegwijzering’. Met het dashboard worden vragen zoals ‘Hoe vaak wordt de looproute en bewegwijzering van ARTIS besproken?’ en ‘Is dit de laatste maanden toegenomen?’ beantwoord. Waar zijn de bezoekers lovend over en waar kan ARTIS extra aandacht aan besteden? Zo weet ARTIS hoe zij zich klaar kan maken voor de toekomst!
AANPAK
Alle responses op de open vragen van de bezoekersenquête zijn verzameld. Hierin zijn eerst de belangrijkste topics geïdentificeerd met behulp van twee topic modellen. Vervolgens zijn aan elk respons de topics toegewezen die hierin voorkomen door middel van semi-supervised classification. Voor de ‘deep dive’ zijn voor elk onderwerp de meest voorkomende woordcombinaties gevonden, waarbij onderscheid is gemaakt tussen complimenten en verbeterpunten.
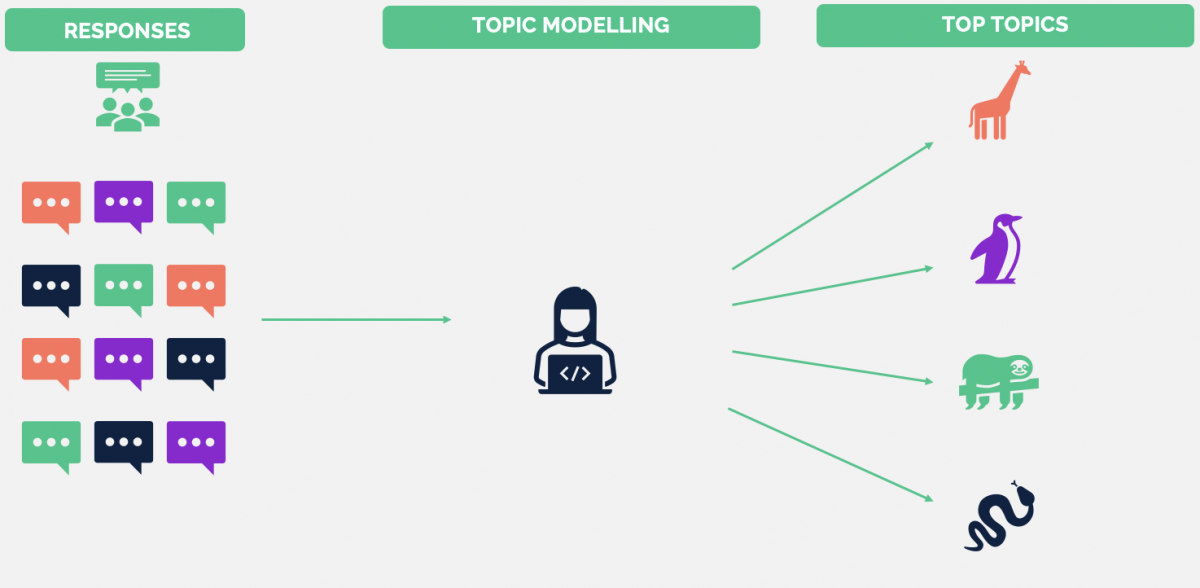
Topic Modelling
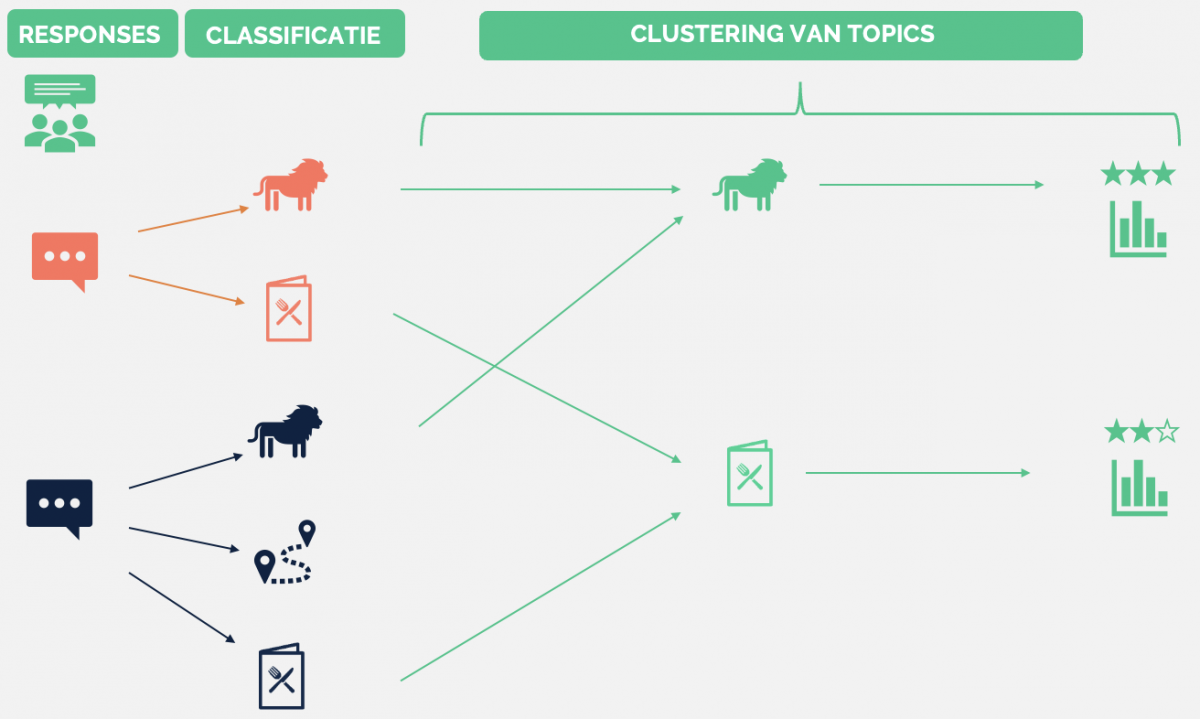
Clusteren van topics
