Slachtofferhulp Nederland
Voor een organisatie als Slachtofferhulp is het van groot belang dat ze slachtoffers zo goed mogelijk kunnen helpen. Daarom hebben wij vanuit ons initiatief Data for Good gewerkt aan een webscraper: deze computertechniek verzamelt, indexeert en analyseert online uitspraken automatisch en presenteert deze informatie vervolgens in een webapplicatie. Werknemers hebben sneller toegang tot relevante informatie en kunnen daardoor nauwkeurig te werk. Zo krijgen slachtoffers de emotionele of juridische hulp die ze nodig hebben.
Gebruikte technieken: Python, Azure, Flask, HTML, JavaScript, SQL, Docker, Gunicorn, TensorFlow, Scikit-learn & Elasticsearch
VOORSPELLEN VAN WERKVOORRAAD.
PROBLEEM
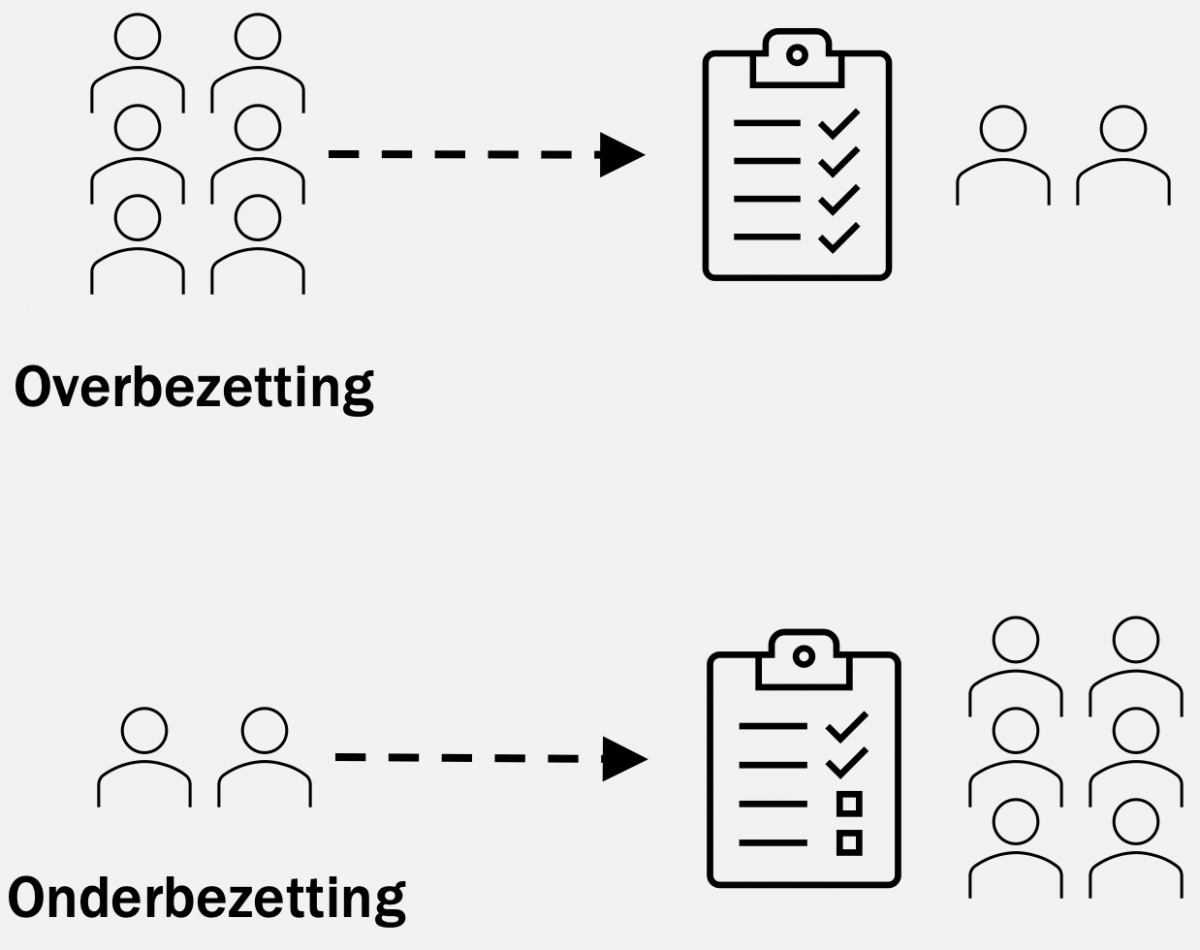
Bij Slachtofferhulp Nederland zijn veel vrijwilligers werkzaam. Om de planning te optimaliseren is het doel zo veel mogelijk onder- en overbezetting te voorkomen. Uit dit doel is de wens ontstaan om beter inzicht te krijgen in de toekomstige werkdruk per werknemer (werkvoorraad). Om dit te realiseren is de eerste stap ‘het voorspellen van de doorlooptijd van nieuwe taken’. De doorlooptijd is gedefinieerd als de tijd tussen het creëren van een taak en het realiseren van deze taak.
RESULTAAT
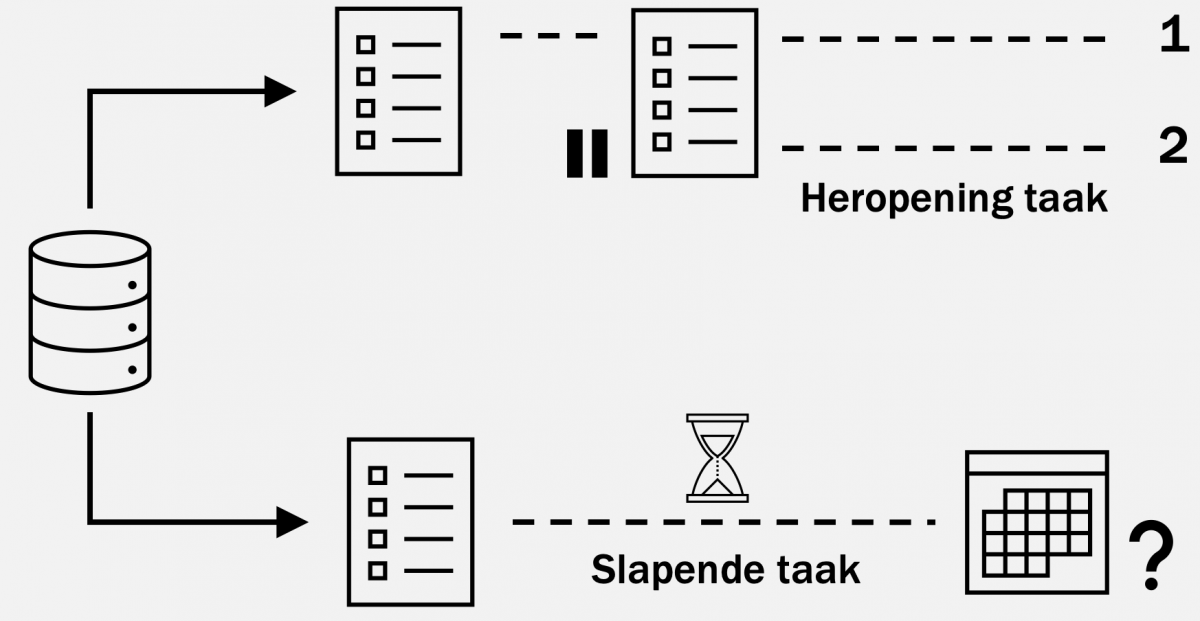
In de data die beschikbaar is vanuit Slachtofferhulp zit niet genoeg voorspellende waarde om voorspellingen te doen die daadwerkelijk effect hebben op de werkvoorraad. Zo komt het regelmatig voor dat taken afgesloten worden en vervolgens heropend worden als een nieuwe taak. Het gevolg is dat twee losse taken overblijven terwijl er eigenlijk maar één taak open hoort te staan. Verder bestaat het probleem van ‘slapende’ taken. Dat zijn taken waarop geen daadwerkelijk werk wordt verricht, maar die alsnog open blijven staan in afwachting van bijvoorbeeld een aanstaande zitting. Gemiddeld gezien zitten de voorspellingen ruim 20 dagen naast de echte doorlooptijd van de taken. Dit is een te grote afwijking om beleid op te voeren.
AANPAK
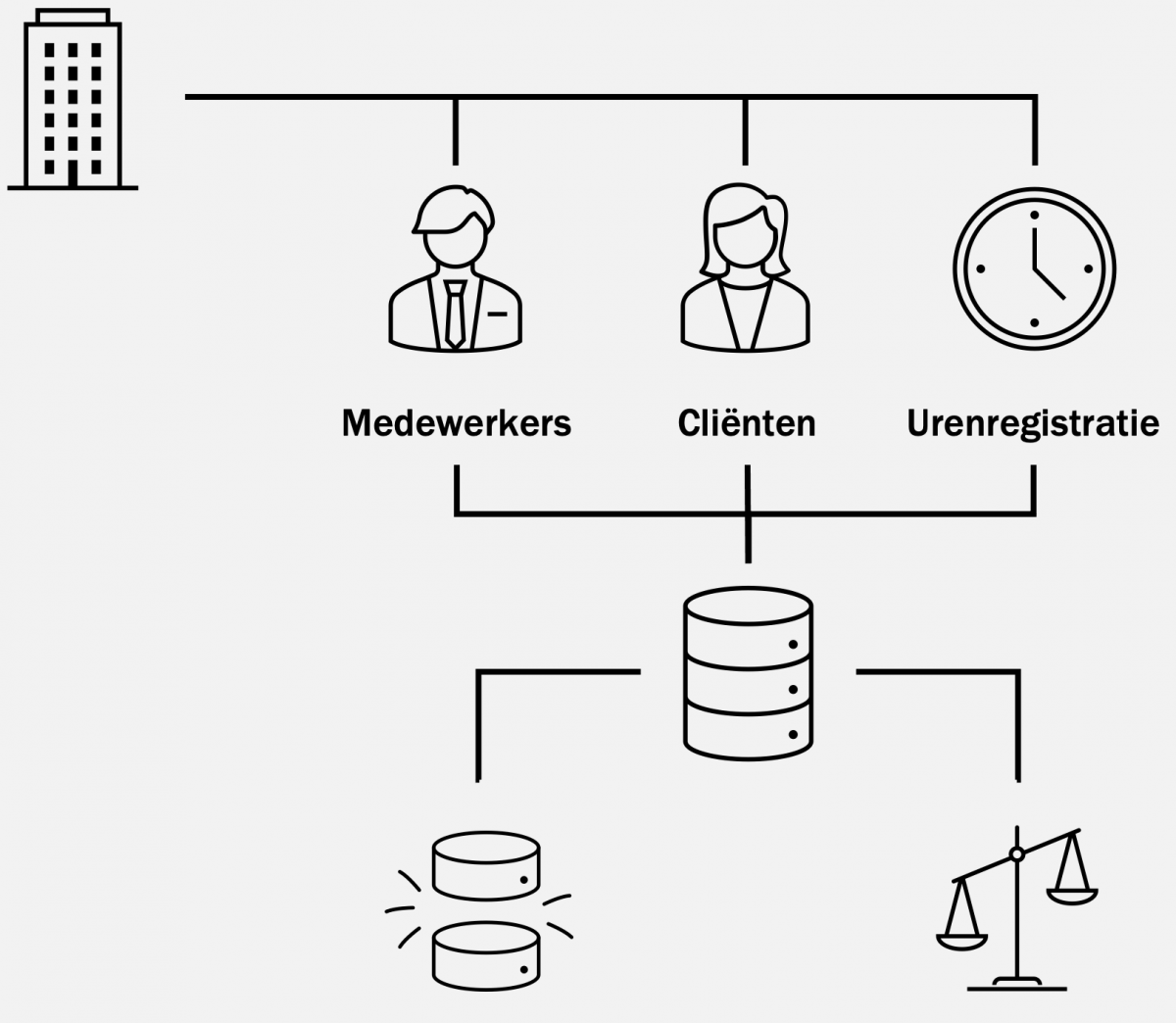
Voor het project is data uit diverse databronnen verzameld. Hierbij zijn drie interne bronnen ingezet, waaronder: cliëntgegevens (CRIS), medewerker gegevens (Youforce) en urenregistratie (TIM). Om deze data te combineren en om te zetten naar een voorspelmodel, is het belangrijk om de variabelen begrijpelijk te maken voor de computer, waaronder de omgang met missende waardes en categorieën die extra zwaar wegen. Dit noemen wij preprocessing & feature extraction. Vervolgens werd gekeken hoe deze features invloed hadden op de doorlooptijd van een project. En is hier een voorspel model voor ontwikkeld
SCRAPEN VAN ONLINE GERECHTELIJKE UITSPRAKEN.
Slachtofferhulp Nederland zoekt naar een manier om online gerechtelijke uitspraken efficiënter te kunnen beoordelen, waarbij het gestructureerd opslaan van deze data in een database als zeer gewenst bijkomend voordeel wordt gezien. Dit omdat het doorzoeken van de jurisprudentie op deze manier eenvoudig wordt. Daarnaast biedt het onderhouden van een dergelijke database veel andere kansen om interessante informatie uit te vergaren.
Allereerst dient bij dit project de jurisprudentie periodiek verzameld te worden die online door de rechtspraak gepubliceerd wordt. De ‘nieuwe’ jurisprudentie dient weggeschreven te worden naar een database waarna deze vervolgens geanalyseerd en verrijkt kan worden met features als bijvoorbeeld een schadebedrag, rechtbank/gerechtshof, rechters, uitspraak, etc.
Vervolgens moet het type delict bepaald en getoond worden aan de eindgebruiker een voorstel te kunnen doen van het type delict bij een uitspraak. Om dit te kunnen doen is een dataset nodig om op te trainen gebruik makende van de extra verkregen features.
Tot slot moet dit alles nog in een applicatie gepresenteerd worden aan de eindgebruiker. Enkel deze eindgebruikers van de Juridische afdeling dienen toegang te hebben tot deze applicatie waarin ze de benodigde vergaarde informatie overzichtelijk gepresenteerd krijgen om ze efficiënt een juiste beoordeling te kunnen maken. Deze beoordeling dient vervolgens te kunnen worden gemaakt in de applicatie welke dit doorzet naar database, klaar voor andere interne systemen om gebruikt te worden.
PROBLEEM
RESULTAAT
Het project heeft op drie manieren waarde geleverd:
- Het handmatig beoordelen is tijdrovend werk. De ontwikkelde applicatie maakt tijd vrij voor de juridische adviseurs voor complexere werkzaamheden.
- Dit project heeft ervoor gezorgd dat alle jurisprudentie, in een database opgeslagen wordt. Dit geeft meer mogelijkheden tot het uitvoeren van complexe analyses in vervolgprojecten.
- Voor de betrokken werknemers van Slachtofferhulp Nederland was dit een eerste kennismaking met data science. Dit project heeft hen een eerste beeld gegeven van de mogelijkheden en heeft ervoor gezorgd dat zij mogelijkheden binnen de stichting op dit gebied eerder zullen herkennen.
Gebruik makende van ElasticSearch en een schedule in Azure Functions wordt de website van de rechtspraak periodiek opgehaald en gecheckt op nieuwe uitspraken. In Python worden hier met behulp van de NLTK-package bepaalde features uit onttrokken waarna de data d.m.v. pyodbc naar een database in Azure database wordt weggeschreven. Met deze data kan vervolgens een model worden getraind om een delict type te kunnen classificeren bij een uitspraak. Dit model is ontwikkeld met behulp van packages als TensorFlow en Scikit-learn. Het model wordt opnieuw getraind wanneer de scraper nieuwe data heeft opgehaald, maar enkel wanneer er voldoende nieuwe data beschikbaar is. Het getrainde model wordt weggezet in een Azure storage account waar het benaderd kan worden wanneer nodig.
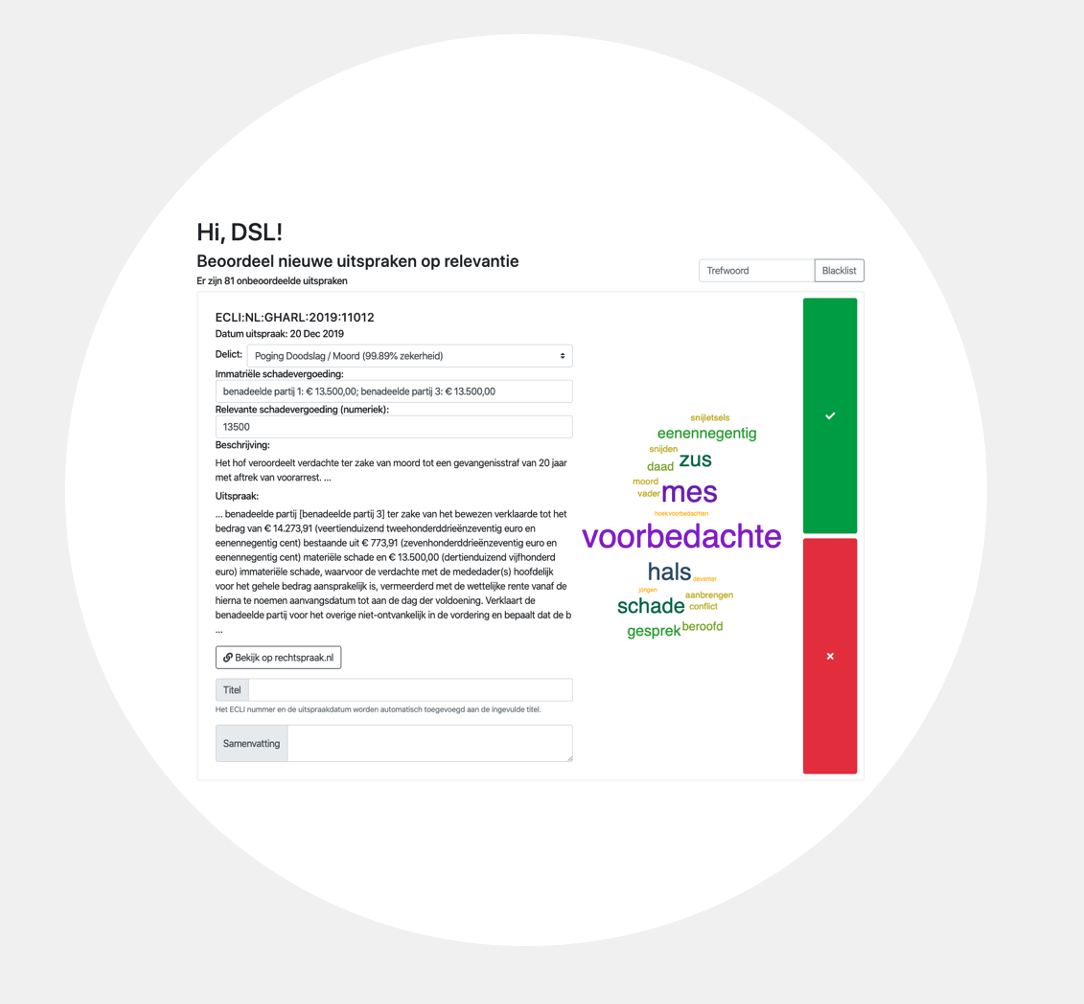
De verkregen resultaten worden vervolgens gepresenteerd in een webapplicatie gehost op Azure. Deze webapplicatie is ‘customized’ ontwikkeld gebruik makende van Flask, Python, HTML en JavaScript. In de vorm van dynamische word clouds worden snelle inzichten verstrekt in de uitspraken. Deze wordclouds kunnen worden gebruikt om irrelevante woorden te markeren, wat weer als input kan worden gebruikt in het voorspellende model. De juiste personen kunnen vervolgens toegang krijgen tot deze applicatie via Azure Active Directory. Om de ontwikkelde applicatie werkelijk te kunnen hosten in Azure wordt gebruik gemaakt van Docker en Gunicorn. Een voorbeeld van een uitspraak getoond in de applicatie is hiernaast te zien.
AANPAK
Gerelateerd artikel

