
VERBETEREN VAN SCANFOUTEN MET WORD EMBEDDINGS.
Het is een veel voorkomend fenomeen; het digitaliseren van data in papieren vorm. Denk hierbij aan boeken, brieven, documenten of kranten. Het voordeel van digitalisering is ten eerste conservering; papier vergaat en bytes niet. Een tweede voordeel is dat gedigitaliseerde data heel makkelijk toegankelijk gemaakt kan worden. Zo hebben wij tegenwoordig digitaal toegang tot 200 jaar oude Nederlandse politieke documenten[1], 400 jaar aan kranten[2],500 jaar oude boeken. Zelfs de populariteit van woorden is momenteel voor ons inzichtelijk[3]. Deze data is niet enkel interessant, het is tevens een goudmijn voor historici, linguïsten en andere wetenschappers. Door digitalisering is deze data een stuk eenvoudiger te gebruiken. In plaats van zoeken door een fysiek archief, kan met één klik op de knop honderden relevante documenten worden opgevraagd.
Digitalisering van geprinte data gebeurt door het inscannen van documenten. De scans worden vervolgens door middel van Optical Character Recognition (OCR) omgezet in een tekstbestand. Dit maakt het mogelijk om bijvoorbeeld tekst te kopiëren of met een zoekterm relevante inhoud te vinden. Zoals de meeste algoritmes en modellen is OCR niet honderd procent correct in het herkennen en extraheren van tekst; er worden soms letters vervangen of spaties onnodig toegevoegd. Dit probleem verergert wanneer de kwaliteit van het gescande papier slecht is (een probleem dat vaker voorkomt bij oude documenten).
Nadelen van lage kwaliteit tekstherkenning liggen voor de hand. Ten eerste zullen de stukken moeilijk leesbaar zijn. De lezer kan over kleine foutjes heen lezen of het juiste woord bepalen op basis van de context. Ideaal is het niet. Een groter probleem doet zich voor als tekstbestanden gebruikt worden door een zoekmachine. Door verkeerd gescande woorden kunnen potentiële matches niet worden gevonden waardoor de bruikbaarheid van de dataset achteruitgaat.

Voorbeeld van een lastig te scannen document; tekst staat dicht op elkaar en de inkt is op plekken vervaagt.
Het foutloos scannen van oude documenten is bijna onmogelijk, daarom zijn er meerdere post-processing technieken om deze onjuistheden na het scannen te verbeteren. Deze verbeteringen kunnen handmatig, semiautomatisch of automatisch worden uitgevoerd.
Digitalisering staten generaal
Het doel van dit project was het ontwikkelen van een automatisch algoritme dat met behulp van ‘word embeddings’ fouten herkent en verbetert. Het algoritme probeert voor ieder woord dat voorkomt in de documenten potentiële foute varianten te vinden. De foutieve varianten worden samen met het input woord opgeslagen in een database. Dit is te vergelijken met een digitaal woordenboek. Als ieder woord door het algoritme behandeld is, kan dit woordenboek gebruikt worden om voor elk fout woord de juiste ‘vertaling’ op te zoeken en zo de fouten te verbeteren. Dit algoritme zou een grote dataset aan Nederlandse parlementaire documenten als input krijgen. Deze documenten zijn in een groot digitaliseringsproject van de Koninklijke bibliotheek online beschikbaar gemaakt onder de naam Staten-Generaal Digitaal[4]. De dataset omvat ruim 2.4 miljoen ingescande en door OCR verwerkte pagina’s aan parlementaire documentatie. De documenten van Staten-Generaal Digitaal bevatten bijna 200 jaar aan Nederlandse politieke geschiedenis – alle parlementaire handelingen van 1815 tot 1995 zijn in deze dataset te vinden.
Het grote nadeel is dat deze documenten op papier van slechte kwaliteit zijn geprint, waardoor de algemene kwaliteit van de data snel achteruit is gegaan. Dit betekent dat er veel fouten tijdens het OCR proces zijn ontstaan die nu aanwezig zijn in de digitale tekst van de documenten.
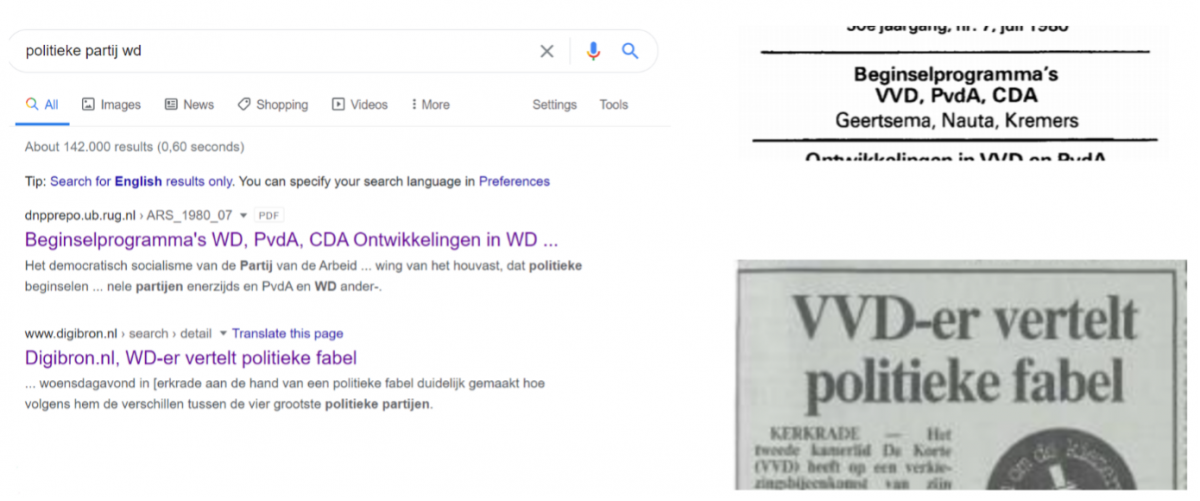
Voorbeeld van een OCR scanfout in het wild: de computer denkt dat er ‘WD’ staat, maar op papier staat er ‘VVD’.
Er kunnen enkele problemen ontstaan wanneer tekstdata over langere periodes van tijd gaat. Zo zijn de eerste paar jaren aan data zowel Nederlands als Frans; tussen 1815 en 1839 was dit de officiële taal binnen Nederland. Naast de meertaligheid van de dataset is de Nederlandse taal door de jaren heen veranderd. Een risico hierbij is dat een model een oude spelling als een verkeerde spelling gaat zien.
De aanwezigheid van twee talen en oude en moderne spellingsvarianten in de dataset kan voor ruis zorgen in de word embeddings. Om de impact van dit probleem zo klein mogelijk te maken is ervoor gekozen om de dataset kleiner te maken. Uiteindelijk zijn alleen de documenten van 1945 tot 1995 gebruikt. Door het weglaten van data uit voorgaande jaren, beslaat de huidige dataset maar 50 jaar aan data, toch zijn dit alsnog 1.2 miljoen pagina’s, bestaande uit 1.1 miljard woorden. Na het filteren van de dataset wordt deze gebruikt om de word embeddings te trainen. De word embeddings van deze dataset worden vervolgens in het algoritme gebruikt om potentiële fouten te vinden.
Word embeddings
Word embeddings betreft een techniek om woorden in een hoog dimensionele vectorruimte te representeren. In deze vectorruimte is het de bedoeling dat woorden met een soortgelijke betekenis dicht bij elkaar staan. De aanname van dit project was dat een woord en de verkeerd gescande varianten dicht bij elkaar staan in de vectorruimte. De embeddings worden getraind op de context waar een woord in voorkomt. Deze context is hetzelfde voor een woord en de verkeerd gescande varianten, dus kan men verwachten dat de embeddings ook op elkaar lijken en in op de assen dicht bij elkaar staan. Hieronder is te zien dat deze aanname klopt; rond het woord ‘minister’ staan – naast andere gerelateerde woorden – ook verkeerd gescande varianten van dat woord.
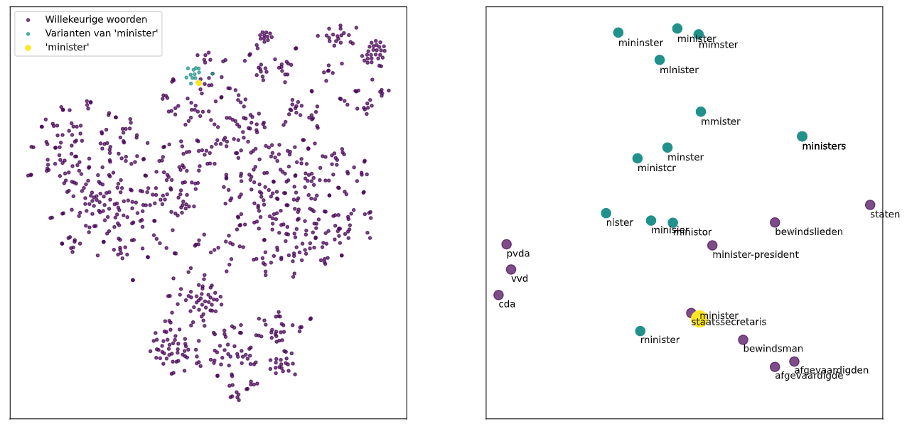
Dimensionaliteitsreductie op een subset van de embeddings laat zien dat woorden en hun verkeerd gescande varianten dicht bij elkaar staan.
Het voordeel van word embeddings is de mogelijkheid om een mate van gelijkheid – of similarity – tussen embeddings te berekenen. Door deze similarity is het mogelijk de gelijkenis van twee embeddings in een getal uit te drukken. Word2vec[5] – de techniek gebruikt om embeddings te trainen – gebruikt de cosine similarity[6] om de gelijkenis tussen embeddings te berekenen. Deze similarity score kan een waarde hebben tussen -1 en 1, waar een similarity van 1 betekent dat twee embeddings hetzelfde zijn, en een similarity van -1 dat de embeddings tegenovergesteld van elkaar zijn. Door deze similarity scores is het mogelijk om woorden die qua context op elkaar lijken te herkennen. Dit kan dus gebruikt worden om scanfouten te herkennen; deze scanfouten hebben een embedding die erg lijkt op de embedding van het correcte woord. Maar alleen een gelijkenis tussen embeddings is niet genoeg, zo zou het woord ‘staatssecretaris’ als scanfout van ‘minister’ herkend worden omdat de embeddings op elkaar lijken. Naast een embedding similarity is er nog een andere mate van gelijkheid nodig om een foute variant van een woord te herkennen.
Edit distance
Alleen kijken naar hoe dichtbij embeddings bij elkaar staan is niet genoeg om potentiële OCR fouten te herkennen. In voorgaande afbeelding is te zien dat ook correcte woorden dicht bij ‘minister’ staan. In grote lijnen wil je dat het algoritme alleen woorden gaat verbeteren die qua lettergebruik en opbouw lijken op het woord dat als input wordt gegeven. Zo wil je bijvoorbeeld ‘staatssecretaris’ niet verbeteren naar ‘minister’, deze woorden lijken compleet niet op elkaar. De woorden ‘minisier’ of ‘ministor’ daarentegen lijken erg op ‘minister’, deze wil je wel door het algoritme laten verbeteren.
Een manier om deze ‘fysieke’ gelijkenis van woorden in een getal uit te drukken is de Levenshtein- of edit distance[7]. Het edit distance algoritme berekent hoeveel edits er nodig zijn om woord A naar woord B te veranderen. Een edit is bijvoorbeeld het toevoegen of weghalen van een letter, of een letter door een andere te vervangen. Een lage edit distance betekent dat de woorden op elkaar lijken. Zo zitten ‘minisier’ en ‘ministor’ maar één edit af van ‘minister’, terwijl ‘staatssecretaris’ er 13 edits van af zit.
Het algoritme
Nu de twee technieken – die dienen om de woordgelijkenis te berekenen – zijn gedefinieerd, is het mogelijk om het algoritme te maken. Voordat een woord door het algoritme gaat, wordt eerst door middel van het embedding model een top 100 meest gelijke woorden, de ‘kandidaten’, gevonden. Deze initiële groep kandidaten wordt dan gefilterd door middel van een maximale edit distance. De edit distance tussen het input woord en de kandidaten mag maximaal 2 zijn wanneer het input woord 6 letters of langer is. Als het input woord korter is dan 6 letters dan is de maximale edit score 1. Dit is gedaan omdat twee edits bij korte woorden veel kan veranderen; het algoritme moet hier iets preciezer zijn. De kandidaten worden vervolgens gefilterd door een minimumgrens op de cosine similarity tussen de input en de kandidaten te stellen. Na deze twee filters blijft een groep over die het algoritme ziet als potentiële foute varianten van de input.
Naast de filters op woordgelijkenis worden er ook een paar heuristieken gebruikt om de kwaliteit van de verbeteringen te optimaliseren. Zo worden bijvoorbeeld getallen niet behandeld omdat er geen manier is om op basis van de context te bepalen of het cijfer correct is of niet. Ook is de assumptie gemaakt dat de juiste variant van een woord altijd het vaakst voorkomt; als een door het algoritme herkende ‘potentiële fout’ vaker voorkomt dan het input woord dan wordt deze niet meegenomen in het woordenboek. Een overzicht van hoe het algoritme werkt is in de volgende afbeelding te zien.
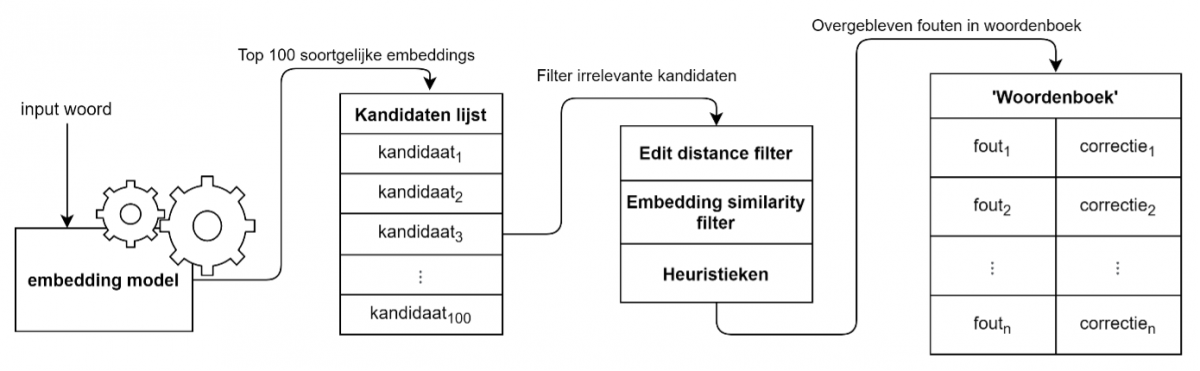
Visueel overzicht van het algoritme.
Nadat het algoritme ieder woord heeft gezien, bestaat het woordenboek uit een groot aantal fout-correctie paren. Deze paren worden geëvalueerd door middel van een evaluatie set die bij de dataset hoort. In deze evaluatie set zitten automatisch gegenereerde fout-correctie paren. Omdat ook deze set automatisch gegenereerd is zitten hier ook foutjes in, zo blijkt dat ongeveer 10% van de paren van het algoritme wel correct waren, maar niet in de evaluatie set zaten. Dit is doorgerekend in de uiteindelijke scores van het algoritme.
Resultaten
De evaluatie van het algoritme is op twee manieren berekend. Als eerste is de performance van het algoritme uitgedrukt in de gebruikelijke precisie, recall, en F1 scores. Deze score is berekend per cosine similarity grens, om zo een gevoel te krijgen voor wat de beste waarde is; een hoge of lage grens. Deze scores zijn berekend op type level, dit wil zeggen dat elk fout-correctie paar 1 keer meetelt, ook als de woorden vaker dan 1 keer voorkomen in de tekst. De scores zijn hieronder te zien. Hier is te zien dat een cosine similarity grens voor deze dataset het best op 0.65 gezet kan worden.
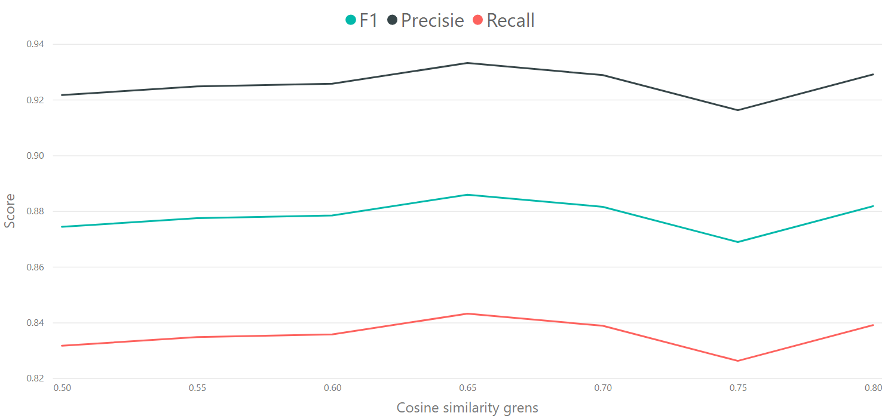
Performance scores per cosine similarity grens.
Omdat deze scores redelijk abstract zijn is het belangrijk om de toegevoegde waarde van het algoritme uit te drukken in het aantal fouten dat het verbetert. Door de dataset tegen een Nederlandse woordenlijst aan te houden weten we dat er ongeveer 23.2 miljoen foute- of niet bestaande woorden in de teksten staan. Door ook de woordfrequenties mee te nemen in de precisie score kunnen we berekenen hoeveel fouten er door het automatische algoritme verbeterd worden; dit zijn er 11.1 miljoen. Er kan dus gezegd worden dat dit algoritme automatisch net iets minder dan 50% van de fouten verbetert.
Verbeteringen
Ondanks dat deze resultaten goed zijn, is er nog genoeg ruimte voor verbetering. Zo is bewust gekozen om geen gebruik te maken van bestaande woordenlijsten of andere externe data. Dit onderzoek was een proof-of-concept om te kijken hoever men kan komen met alleen de gegeven dataset en een slim algoritme. Het gebruik van een externe woordenlijst zou wel veel verbetering brengen; het kwam voor dat een herkende fout een correct woord was. Een voorbeeld hiervan is bijvoorbeeld ‘enerzijds’ en ‘anderzijds’. Deze woorden betekenen vrijwel hetzelfde, dus de embeddings lijken op elkaar en ze zitten 2 edits van elkaar af. Dit soort fouten van het algoritme kunnen makkelijk voorkomen worden.
Een andere verbetering is te vinden in de techniek om de word embeddings te trainen. Tegenwoordig is word2vec ingehaald door slimmere en betere algoritmes die hogere kwaliteit embeddings zouden genereren. Deze betere embeddings zouden, samen met externe data, kunnen zorgen dat het aantal verbeterde fouten omhooggaat.
Verwijzingen
[1] https://www.staten-generaal.nl/begrip/staten_generaal_digitaal
[2] https://www.delpher.nl/
[3] https://books.google.com/ngrams
[4] http://www.statengeneraaldigitaal.nl/
[5] https://radimrehurek.com/gensim/models/word2vec.html
[6] https://en.wikipedia.org/wiki/Cosine_similarity
[7] https://en.wikipedia.org/wiki/Edit_distance
