

DeepSeek has spectacularly positioned itself as a formidable competitor in the world of Large Language Models (LLMs). With stock prices surging and political tensions flaring, you could hardly ignore DeepSeek in recent weeks. But what makes this model so special? Is it truly revolutionary, or simply a budget-friendly version of market leaders such as OpenAI’s ChatGPT? In this blog, we look at DeepSeek’s technical architecture and analyze why these models are so efficient and fast.
DeepSeek vs. market leaders
While market leaders such as OpenAI, Meta and Google put tens of billions into developing LLMs, DeepSeek claims to have trained its newest model for just a few million. And yet it manages to come surprisingly close to the performance of these established names. DeepSeek has thus achieved an impressive combination: the power and accuracy of leading AI models, such as the OpenAI-o1, but with remarkable efficiency and scalability. We have not seen such a balance between performance and cost savings on this scale before.
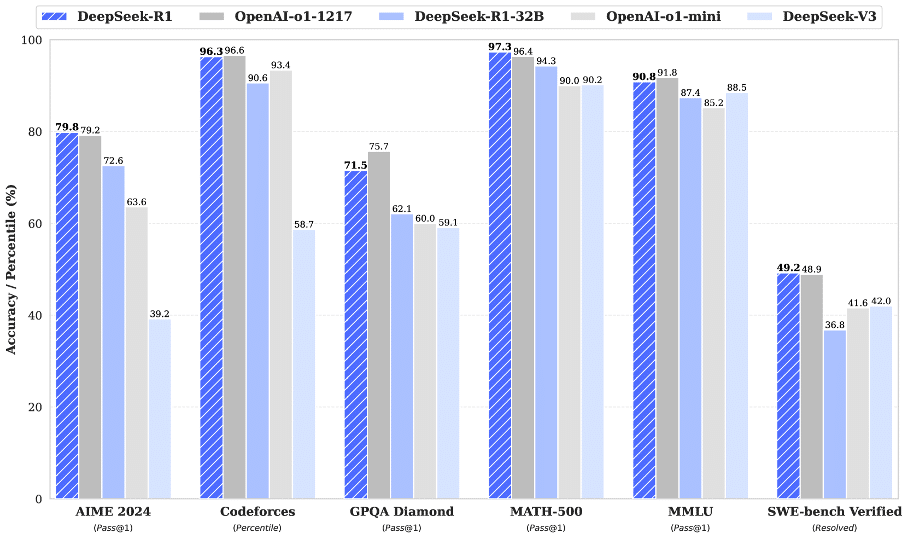
Figure 1: Benchmark performance of DeepSeek-R1(DeepSeek-R1).
How does DeepSeek work?
To understand why DeepSeek is so fast and efficient, we dive into its underlying architecture. Like most advanced LLMs, DeepSeek is based on the Transformer architecture(Vaswani et al., 2017). But where conventional AI models activate every neuron/parameter in the network with every input, DeepSeek takes a different approach with a Mixture-of-Experts (MoE) architecture. Here, only a small selection of specialized subnetworks — the “experts” — are activated per input. Which experts are selected depends on their relevance to the current input.
This innovative mechanism dramatically reduces the computing power required and increases the speed of the model without sacrificing performance. For example, DeepSeek-V3 contains 671 billion parameters but activates only 37 billion per token – only 18% of the total model.
DeepSeekMoE: The engine behind efficiency
DeepSeekMoE is the brains behind DeepSeek’s impressive efficiency. It is DeepSeek’s proprietary MoE model. DeepSeekMoE consists of multiple experts and a gating mechanism that determines which experts are activated per input (see Figure 2).
Traditional MoE models suffer from two major problems:
- – Knowledge Hybridity – Experts learn overlapping concepts, blurring their specialization.
- – Knowledge Redundancy – Multiple experts store the same information, causing wasted resources.
DeepSeekMoE solves these barriers with two core innovations:
- – Fine-Grained Expert Segmentation – By further splitting experts into smaller, specialized units, redundancy is reduced and the model learns more efficiently. In addition, this minimizes the learning of redundant or duplicate information.
- – Shared Expert Isolation – A subset of experts is kept constantly active to store general knowledge, allowing the rest of the model to focus on specialized tasks.
Thanks to these innovations, DeepSeekMoE achieves performance comparable to dense models, but with significantly less computing power. For example, DeepSeekMoE 16B performs as well as LLaMA2 7B while consuming 40% fewer computational resources. This makes the model not only powerful, but also more scalable and efficient than many traditional alternatives.
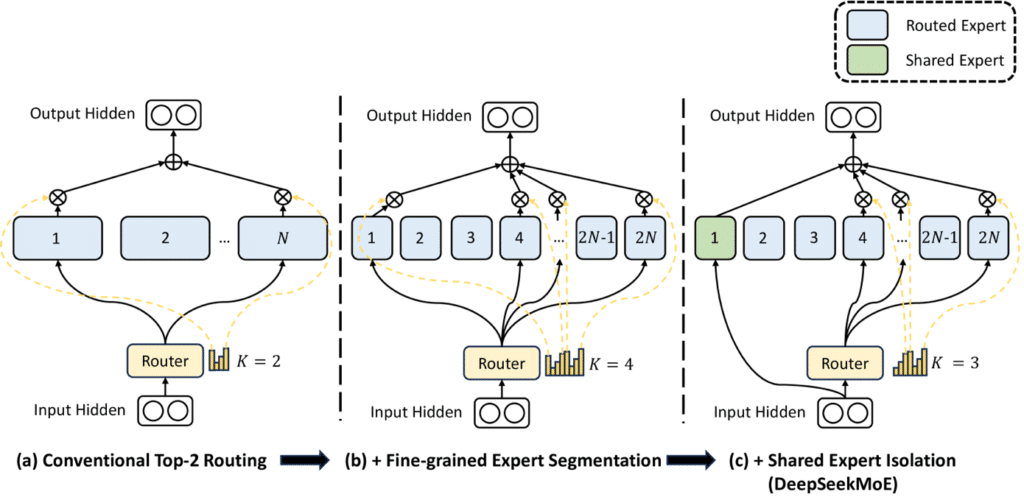
Figure 2: Visualization of DeepSeekMoe (subfigure c). For all three architectures, the number of parameters and computational cost are otherwise the same.(DeepSeekMoE)
How are experts getting smarter?
DeepSeek uses an advanced training process with gradient-based optimization. Unlike conventional neural networks, in DeepSeek, only activated experts receive updates, allowing them to quickly specialize in certain tasks. Thus, the experts learn only from input that is relevant to them.
Training process
- 1. Token routing
- The gating function determines which experts are activated per token.
- 2. Forward pass
- Only the selected experts process the token and generate the output.
- 3. Backpropagation & learning
- The gradients of the experts and gating function are updated by the corresponding loss.
- Expert weights -> Each expert learns only from the tokens he himself processes.
- Gating function -> learns to improve expert allocation.
The experts specialize by:
- – Gating function assignments – Similar inputs are directed to the same expert subset.
- – Reinforcement of patterns – Each expert fine-tunes his responses based on frequent data types.
- – Regularization techniques – Prevents some experts from being overused and others from being underutilized.
Because inputs with specific characteristics or traits are constantly sent to the same expert, that expert becomes specialized in a particular task. For example, one expert develops a specialization in programming code, another in legal writing and a third in everyday conversation.
A common risk during this process is that some experts are over-questioned while others remain questioned. This reduces the efficiency and generalization of the model. To overcome this, DeepSeek uses load balancing techniques, such as auxiliary losses (DeepSeekMoE) where overquerying an expert is penalized, and bias-adjusted routing (DeepSeek-V3), where each expert is given a dynamic bias term based on the load.
In short, experts in DeepSeek models improve themselves by:
- – Processing similar data over time (natural specialization).
- – Receiving targeted gradient updates (reinforces expertise).
- – The use of load balancing techniques (efficient contribution of all experts).
Ultimately, the specialized experts lead to:
- – Improved quality of responses.
- – Scalability.
- – Real-time optimization of resources which accelerates the model and reduces costs.
DeepSeek-V2 and DeepSeek-V3
DeepSeek has further refined its architecture in DeepSeek-V2 and DeepSeek-V3. These models introduce new innovative features such as:
- – Multi-Head Latent Attention (MLA).
Multi-Head Latent Attention, a new faster attention mechanism than traditional Multi-Head Attention (MHA). Conventional Transformer models typically use Multi-Head Attention (MHA) (Vaswani et al., 2017), leading to a bottleneck that slows down inference. To overcome this, DeepSeek designed the MLA mechanism for the DeepSeek-V2 and DeepSeek-V3 models (see Figure 3).
- – Auxiliary-Loss-Free Load Balancing.
A more efficient alternative to auxiliary loss functions. Many MoE models, and so does DeepSeekMoE, require auxiliary loss functions to avoid overloading some experts while leaving others unused. DeepSeek-V3 solves this by introducing the bias-adjusted routing strategy, which improves efficiency without sacrificing load balancing.
- – FP8 Mixed Precision Training
DeepSeek uses FP8 mixed precision arithmetic to reduce memory usage and decrease computation time. Computations are split between lower and, where necessary, higher precision, leading to a balance between efficiency and numerical stability.
- – Multi-Token Prediction (MTP).
With Multi-Token Prediction, the model predicts multiple future tokens simultaneously, speeding up both training and inference. In traditional LLMs, this is one token at a time.
- – Advanced Training Infrastructure
An infrastructure to overcome GPU bottlenecks and enable efficient training at extremely large scales. DeepSeek-V3 is trained with a DualPipe pipeline parallelism. Combining this with an optimized cross-node communication system makes DeepSeek-V3 one of the most efficient large-scale MoE models to date.
The differences between the three variants
Briefly, the differences between these three variants of the models are as follows:
- – DeepSeekMoE is the basic version that works with a traditional MoE architecture and auxiliary loss functions for load balancing.
- – DeepSeek-V2 introduces improved routing, FP8 mixed precision, and Multi-Token Prediction for more efficient training and inference.
- – DeepSeek-V3 goes one step further with bias-adjusted routing, more advanced mixed precision and improved infrastructure for extreme-scale training, further optimizing efficiency.
DeepSeek-V3 is thus the most advanced model and combines the innovations for maximum performance and efficiency. (see Figure 4).

Figure 3: Simplified visualization a number of attenion mechanisms, with Multi-head Latent Attention (MLA) on the far right. By compressing the keys and values together into a latent vector, MLA makes the inference process significantly faster.(DeepSeek-V2)
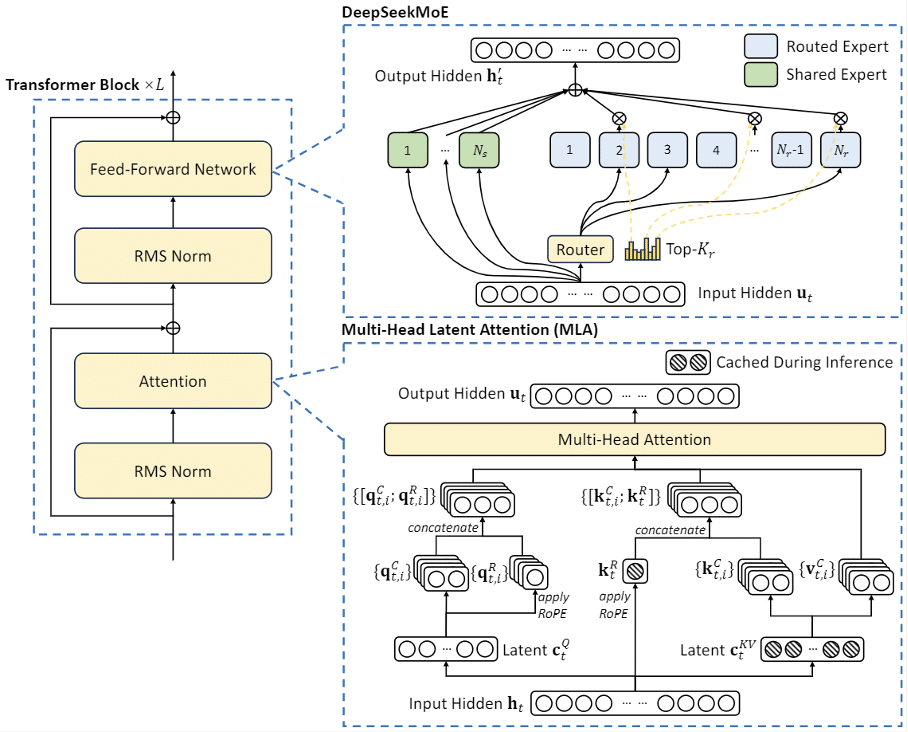
Figure 4: The basic architecture of DeepSeek-V2 and DeepSeek-V3(DeepSeek-V2).
DeepSeek-R1: a technological milestone
DeepSeek-R1 is the model that made the real breakthrough. A breakthrough that not only rocked the AI community, but also had a broad societal impact. From plummeting stock prices to heated political debates about the future of AI, DeepSeek-R1 proved that it was not just another new model, but a technological milestone.
This model uses Reinforcement Learning (RL), which allows it to reason and make decisions independently. This not only takes performance to the next level, but also shows what is possible when you let the model think for itself.
In terms of architecture, DeepSeek R1 is identical to the DeepSeek-V2 and DeepSeek-V3 variants. It uses the “only-pretrained” version of these models, but then has its own post-training process.
Simply put, the developers built a test-verification harness around the model and applied an RL process to it. The model learns by being rewarded for good outcomes. During this process, they used a simple reward function (RL equivalent of a loss function). The function is a weighted sum of two components:
- – Accuracy Reward – If the task has an objectively correct answer (such as a mathematical problem), the correctness is verified by several appropriate tests. The model is rewarded for correctness.
- – Format Reward – The model is rewarded for following a structured reasoning process.
Using this post-training process leads to:
- – Self-verification – The model double-checks its own answers.
- – Extended chain-of-thought – The model learns to explain its reasoning more thoroughly.
- – Exploratory reasoning – The model examines multiple approaches before reaching a conclusion.
- – Reflection – The model questions its own solutions and adjusts its reasoning process.
Thanks to this process, DeepSeek-R1 is not only accurate, but also more reliable in generating structured and controlled outputs.
The final model
As a result, the final model has:
- – A strong chain-of-thought for verifiable tasks.
- – Tuning to diverse user requests in daily use.
- – Safer and more controlled outputs.
Challenges and risks
While DeepSeek offers great potential, it also brings challenges and risks:
1. Security Risks in Open-Source
DeepSeek is open-source. This is both a strength and a risk. Despite the fact that this makes it transparent and allows for customization, at the same time the model is also more vulnerable to misuse for malicious purposes, such as generating disinformation, spam or unethical automation.
2. Ecosystem and Support for Developers.
Compared to proprietary models (such as OpenAI’s GPT-4), DeepSeek has a smaller ecosystem of integrations, tools and community support. This may make it harder for DeepSeek to compete with larger models in the long run. Adoption rates and real-world testing are going to determine whether the model can effectively compete with larger competitors in the long run.
3. Bias and Language Limitations
The model is highly optimized for English and Chinese, which may affect performance in other languages.
Multiple articles quickly appeared demonstrating Chinese government interference and censorship (including CNN, The Guardian). There were also privacy concerns, including data breaches, which led to imposed restrictions on the use of DeepSeek (mainly in professional settings) in several countries (e.g., Wiz, NowSecure, BBC).
In short, DeepSeek offers great potential as an open-source alternative to the closed-source LLMs that have led the market so far, but its long-term success depends on continuous improvements in accuracy, security and ecosystem growth.
The future of DeepSeek
DeepSeek proves that open-source AI models can compete with proprietary models. It offers a new perspective on efficient, scalable AI while raising discussion about transparency, security and ethics in AI development.
With DeepSeek-V3, the company shows that open-source models can not only keep up, but possibly even define the future of AI. The unique combination of high performance, scalability and efficiency makes DeepSeek revolutionary. Whether you are a researcher, developer or entrepreneur – DeepSeek is changing the way we think about Large Language Models. In fact, we can say that DeepSeek has set a new standard.
Moreover, DeepSeek’s open-source and efficient nature certainly makes it attractive for business applications in addition to research. More on that in a later blog. Are you already curious how your organization can take advantage of these developments? We would love to help you out! Make an appointment with us and discover the possibilities.


