

What are the possibilities of GenAI, Large Language Models (LLMs) for the internal organization? How to implement an LLM effectively for organizations. Not just as a “nice to have,” but to make sure they can work more efficiently and effectively with the application. In other words, a step forward.
There are many processes that take time that can be done efficiently by an LLM. We have talked before about an LLM for your knowledge management. A good example of how to make your knowledge base accessible to your organization in an efficient way. In this blog I, Dave Meijdam (Data Scientist), will take you through the added value of an internal LLM in combination with RAG for Fokker.
Fokker case highlighted
Imagine that a Program Manager at Fokker is looking for specific details of a contract written several years ago. Instead of flipping through various folders and documents, he/she can simply ask the LLM a question. Such as “What are the key terms of the contract with vendor X for project Y?”. The LLM, supported by RAG, then retrieves the relevant document and provides a summary of the requested information. This not only speeds up the process, but also ensures accurate and traceable information.
Another example is the Customer Support team that needs quick information about the warranty terms of a specific aircraft part. With a centralized knowledge base and an LLM, they can easily ask questions like “What are the warranty conditions for part Z?” You immediately get an accurate answer based on the most recent and relevant documents.
In an ideal situation, Fokker has a central knowledge base where everyone can go with questions about processes and agreements. This situation can be created with an LLM implementation, combined with RAG and a knowledge base. With this solution, it is important that the organization can validate the LLM’s answers. In order to create trust and easily detect any errors. Examples include instructions to always name the document name and paragraph number with an answer. Or to understand what pieces of text are retrieved by the RAG system. DSL has implemented part of this system at Fokker, called Anthony Chat.
The Power of Retrieval-Augmented Generation (RAG)
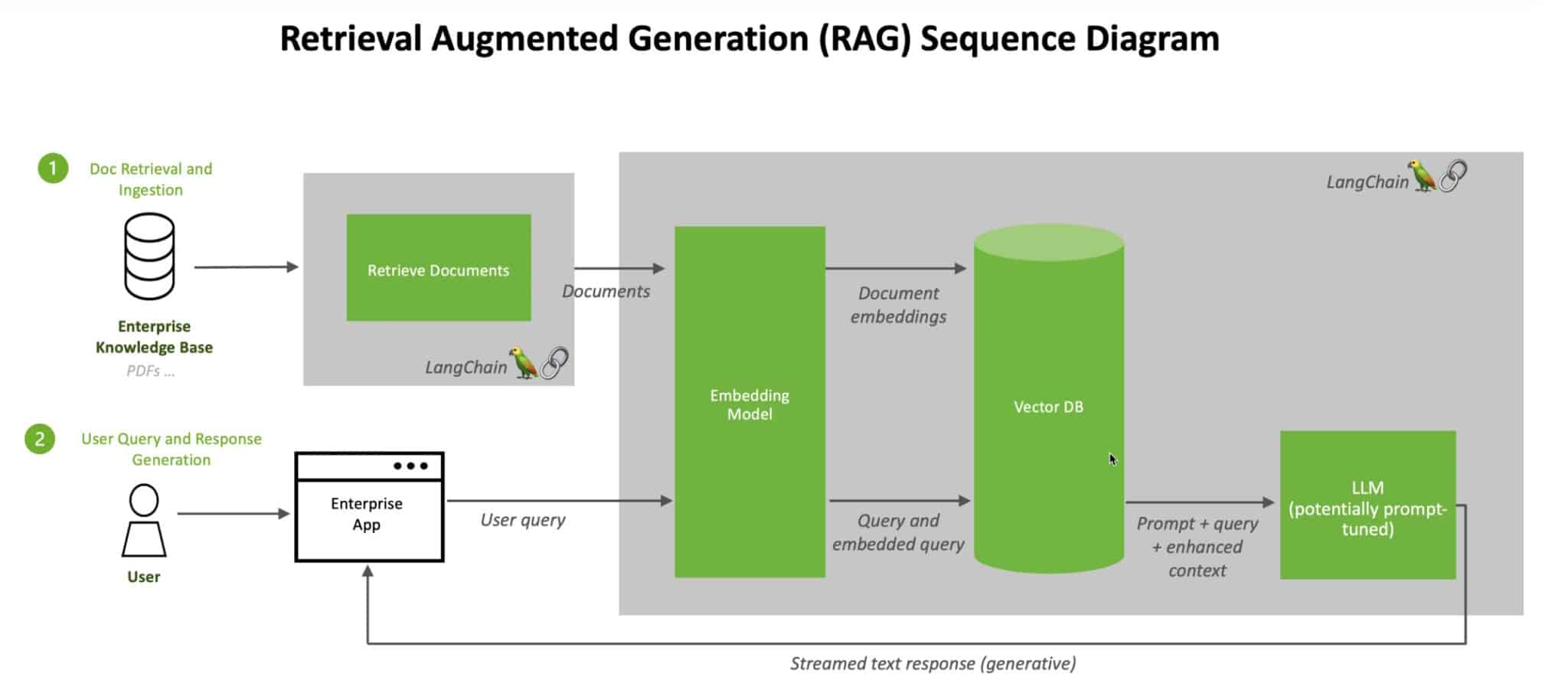
One of the promising technologies in this area is RAG. RAG combines a generative model, such as an LLM, with a retrieval system. This system searches for relevant documents or information from a predefined knowledge base. Then the LLM uses this information to generate an accurate answer. Thus, answers are not only contextually relevant, but also factually correct. Because they are based on the most recent and specific information from the knowledge base.
A knowledge base is an organized collection of information that is easily searchable. Within an organization such as Fokker, the knowledge base consists of legal documents, contracts, manuals, technical specifications and other relevant company documents. By centralizing this information, employees can quickly and efficiently find the information they need. Without having to search through multiple folders and documents. These documents are stored in a vector store.
A vector store is a database specifically designed to store and search text information based on vectors. Instead of traditional search methods that work with keywords, a vector store uses numerical representations (vectors) of the text. These vectors are generated by an embedding model, which converts each sentence or document into a high-dimensional vector.
RAG process explained
The RAG process explained briefly again:
Embedding Documents: Each document in the knowledge base is divided into smaller parts (chunks). These chunks then pass through an embedding model, which converts them into vectors. These vectors represent the semantic meaning of the text, making similar texts close to each other in vector space.
Saving Vectors: The generated vectors are stored in the vector store along with the associated document information (metadata).
Searching with Vectors: When a user asks a question, the question is also converted into a vector by the same embedding model. This query vector is then compared to the vectors in the vector store to find the most relevant chunks. These comparisons are often done using techniques such as cosine similarity, which measures how close vectors are to each other.
Retrieval of Documents: The most relevant chunks are retrieved and used by the LLM to generate an accurate response.
Benefits of internal LLMs combined with a RAG Implementation and a Vector Store as Knowledge Base
The implementation of GenAI or internal LLMs combined with RAG and a vector store as a knowledge base can bring significant benefits to Fokker:
Precision and Relevance: Vector-based search ensures that the most semantically relevant chunks are retrieved, even if they do not contain the exact same keywords as the search query.
Scalability: A vector store can easily handle large amounts of data and can search quickly, even in a very large knowledge base.
Context-aware Queries: Because vectors represent the semantic content of text, the system can better understand and answer complex and contextual queries.
Efficiency improvement: Having a knowledge base allows employees to access needed information faster. This reduces time spent searching for documents and improves overall productivity.
Accurate Information: An LLM using RAG ensures that answers are based on the most relevant information from the knowledge base. This reduces the chances of errors and inconsistencies in the information provided.
Knowledge retention: Centralizing information helps retain knowledge within the organization, especially when employees leave or change roles. This ensures continuity and reduces dependence on individual knowledge carriers.
Learnings & future
Of course, realizing a RAG system is not without its challenges. For example, there was a demand from the organization to ask dozens of queries at once about a document, to quickly retrieve a lot of specific information. With the initial RAG implementation, this did not work optimally: because generic embedding of input was made, not all relevant chunks could be retrieved to answer all questions. As a result, the LLM was able to answer some of the questions and not all of them. To solve this, we added an intermediate step: first, the user input is decomposed, when necessary, into multiple specific questions. Then each question is answered one at a time, and all answers are used as chunks for the final answer.
Another challenge is that contracts can look alike, especially when they are broken down into chunks in a vector store. It is absolutely undesirable for information from another client to be inadvertently used as a chunk in the LLM’s response. To prevent this, it is essential to provide documents and chunks with clear metadata. For example, consider metadata that indicates which customer it is about or, in the case of Fokker, which aircraft parts it is specifically about. To avoid this risk at the moment, the user has to manually select or upload a document. In the future, we want to set up a robust knowledge base, making the manual selection of the correct document unnecessary, thus creating the ideal situation mentioned earlier.
Conclusion
The integration of internal LLMs and RAG within Fokker provides an innovative solution to the challenges of distributed information storage. It improves the efficiency of various tasks, provides consistent and accurate information, supports better decision-making, and helps maintain knowledge within the organization. By embracing this technology, Fokker can not only simplify day-to-day operations, but also strengthen its overall competitive position. At a time when information is the key to success, internal LLMs and RAG provide the tools Fokker needs to stay ahead. Do you also want to lead the way? Contact us.


