

If you watch series like CSI, you probably recognize scenes like this one: detectives are on the trail of the perpetrator and look expectantly at images from security cameras. At first glance, the images don’t seem to show the desired information, but then their eye catches a barely visible detail. They zoom in, improve the image quality and … the detail that then becomes visible reveals important information and provides a breakthrough in the investigation.
This is because images consist of a limited number of pixels and for a sharper image you need more pixels.
If these pixels are not captured, they are also untraceable.
However, today, with the help of Artificial Intelligence, we can get closer and closer to this by making a prediction about these extra pixels; what would the image probably have looked like?
The process of obtaining a high-resolution image from a low-resolution image is called super-resolution.

- Medical imaging (source): due to limitations such as little time or patient movement, the resolution of MRI scans is not always as high as desired.
Super-resolution is therefore being used to improve the quality of MRI scans, which can help doctors make a diagnosis.
- Satellite imaging (source): satellite images are taken from a great distance and are therefore limited in showing detail.
Objects such as cars, for example, are sometimes only 10 pixels in size.
Super resolution can help detect objects better. - Security(source): because HR cameras cannot be placed everywhere, security cameras often provide low-resolution images.
Improving the quality of camera images can help make details – think license plates, for example – more visible.
Classic methods of adding extra pixels to an image generate new pixels based on surrounding pixels.
Unfortunately, super-resolution does not prove to be that simple; these so-called interpolation techniques often result in blurry or pixelated images.
With developments in deep learning methods, the development of super-resolution has taken off in recent years.
Based on a large dataset of images, neural networks can learn to add details to images.
How does that work?
In this blog, we give an introduction to supervised deep learning methods for superresolution.
Data preparation
The first step in supervised learning is to generate a dataset to train a model with.
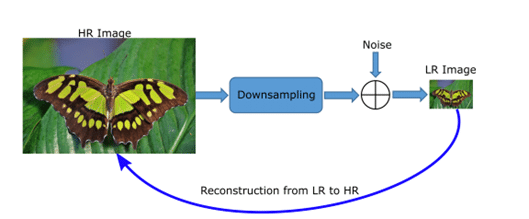
The goal of super-resolution models is to learn a mapping between low resolution (LR) and high resolution (HR) images: in other words, how to turn an LR image into an HR image.
This can be done by giving an LR image as input to the model and an HR image as ground truth; thus, the model can learn a function to get as close as possible to the real image based on an LR image.
Thus, we need LR-HR pairs for training a model.
Such a dataset of LR-HR pairs is often created by taking a set of HR images and applying a function to them to lower the quality of the images.
This can be done by removing pixels, applying blurring and adding noise.
In this way, a good and bad quality version of each image is generated, which we can feed to the model.
Model frameworks
Now that we know what dataset we need, we can start looking at the different types of models we can use for super-resolution.
Super-resolution is a so-called ill-posed problem: an LR image can match multiple HR images; there is no single correct solution.
Therefore, the way of adding pixels, called upsampling , is an important component in the method.
There are roughly four model frameworks with different approaches to upsampling:
- Pre-upsampling: in this method, the LR image is first enlarged (using classical interpolation techniques) to generate a raw HR image.
Convolutional Neural Networks (CNNs) are then used to learn a mapping between this raw HR image and the original HR image.
The advantage of this method is that the neural network only needs to learn this one mapping, since the magnification of the image is done using classical interpolation methods.
The disadvantage of this method is that it can cause blurring.
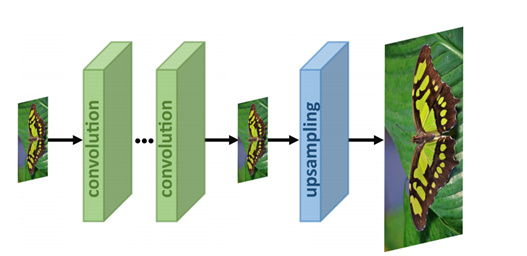
- Post-upsampling: here the LR images go through the convolutional layers first, and upsampling is performed only in the last layer.
The advantage of this approach is that the mapping function is learned in a lower dimension, making the computational processes less complex.
- Iterative up-and-down sampling: here the process of up-and-down sampling is alternated.
Models using this framework are often better at finding deep relationships between LR-HR pairs and therefore often result in better quality images.
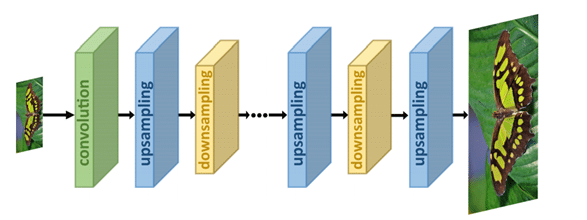
- Progressive upsampling: in this framework, multiple CNNs are used to generate an increasingly large image in small steps.
Breaking down the difficult task into a number of simpler tasks lowers the difficulty somewhat, which can improve results.
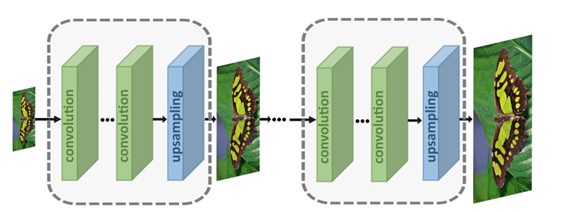
Discussing the different networks carries a bit too far for this blog, but you can consult this resource for more information on them.
Learning Strategies
To train a super-resolution model, it is necessary to be able to measure the difference between the generated HR image and the original HR image.
This difference is used to calculate the error rate in the reconstruction of the HR image to optimize the model.
Loss functions are used for this calculation.
Some examples of such loss functions are:
- Pixel loss: pixel loss is the simplest loss function, where each pixel in the generated image is directly compared to each pixel in the original image.
Since research has shown that this does not fully represent the quality of the reconstruction, other functions are also used. - Content loss: this feature ensures visual similarity between the original image and the generated image by comparing the content rather than the individual pixels.
Thus, using this loss feature ensures better perceptual quality and more realistic images. - Adversarial loss: used in GAN-related architectures.
Generative Adversarial Networks (GANs) consist of two neural networks – the generator and the discriminator – dueling with each other (learn more about GANs? Read it in this blog).
In the case of super-resolution, the generator tries to generate images that the discriminator thinks are real.
The discriminator tries to distinguish the original HR images from the generated images.
This training process eventually results in a generator that is good at generating images that are similar to the original images. - Total variation loss: total variation loss calculates the absolute difference between surrounding pixels and measures the amount of noise in an image.
This function is used to reduce the amount of noise in the generated images.
Evaluation
To evaluate the results of trained super-resolution models, the quality of generated images is measured, there are several methods for this.
Here a distinction can be made between objective and subjective methods.
Because subjective methods often cost a lot of money and time, especially if the data set is large, objective methods are more often used in superresolution.
- Peak signal-to-noise ratio (PSNR): this quantitative metric is based on the individual pixels and gives the ratio of signal to noise.
- Structural similarity index metric (SSIM): also falls under the objective methods and measures the structural similarities between images by comparing contrast, light intensity and structural details between images.
- Opinion scoring: a subjective method in which people are asked to rate specific criteria such as sharpness, color or natural appearance.
Discussion
Now that we have discussed a number of methods for training super-resolution models using deep learning, you may be thinking: wow, with super-resolution we can conjure up all sorts of details like this that we couldn’t otherwise see!
In practice, things are just a bit more complicated.
A while back, the photo below circulated on social media:

On the right we see the result of a super-resolution model trained on faces, a white man.
Discussion flared up because, like many other applications of AI, this shows the danger of bias: this super-resolution model produced white faces much more often than faces of any other color.
What happened here?
Rather than “improve” the low-resolution image, the model generates a completely new face that looks the same in low resolution as the input image.
The bias that is in the dataset on which the model is trained is reflected in the results.
So it is important to realize that with super-resolution we are not making a true reconstruction, we are making a guess based on information gained from a dataset.
It is still “made-up” information, so we have to be careful about the conclusions we draw from it and think carefully about what purposes we can and cannot use it for.
References
- Reeth et al. 2012: https://onlinelibrary.wiley.com/doi/epdf/10.1002/cmr.a.21249
- Bashir et al. 2021: https://arxiv.org/abs/2102.09351
- Yue et al. 2016: https: //www.researchgate.net/publication/303182546_Image_super-resolution_The_techniques_applications_and_future
- Shermeyer et al. 2019: https://arxiv.org/abs/1812.04098
- Gohshi 2015: https://www.scitepress.org/Papers/2015/55598/55598.pdf


