

Image recognition has a problem
Traditional computer vision models work well for specific tasks, but generalize poorly. A model that recognizes cats and dogs cannot easily recognize humans. Even ImageNET a dataset with 1,000 categories, has its limitations. For example, it does not recognize people, let alone distinguish between a child and an adult. But now there is CLIP.
CLIP: Generalization in image recognition
Contrastive Language-Image Pre-training (CLIP), developed by OpenAI, addresses this problem. CLIP is designed as a general model that understands images without specific training for each category. It recognizes not only cats and dogs, but also abstract concepts such as “an astronaut on a horse in space.” This makes it a powerful computer vision model: instead of training multiple models for different tasks, CLIP provides a one-size-fits-all solution. A similar architecture is also used in GPT-4 for image processing.
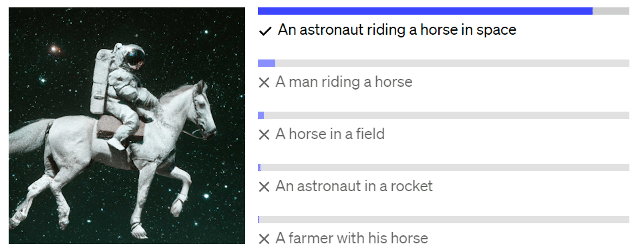
Image 1. Best matching description to image according to CLIP
How CLIP works
OpenAI describes CLIP as
Those zero-shot capabilities mean that it can recognize concepts it has never seen before. For example, the model has never seen a picture of an “astronaut on a horse in space,” but it knows what an astronaut, a horse and space are. By combining these concepts, it can assign the correct classification. To understand how CLIP achieves this generalization and how it matches images with text, we dive deeper into the technique.
Under the hood
CLIP links text and image via embeddings-numeric representations of data-in a high-dimensional space. In this space, matching images and text are close together. This makes it possible to perform tasks such as image description, object detection and classification. When classifying an image, it compares the image embodiment with textual descriptions such as “A photo of a dog” and “A photo of a cat.” The model chooses the description that best matches the image.
CLIP is trained on 400 million image-text pairs retrieved from the Internet. This provides an advantage over traditional datasets with simple labels such as “cat.” CLIP’s dataset contains richer descriptions, such as “a sleeping cat on a chair” or “a cat playing with a ball.” This allows the model to learn not only what a cat is, but also what a chair or a ball is.
Converting these image-text pairs to usable embeddings is done in a step called Contrastive pre-training . In this step, it is trained to match real image-text pairs within a batch of N random pairs from the dataset. In this step, a text and image encoder transform their input to an embedding. The goal is for the embeddings of the image and the text of pair 1 to be the same for all pairs in the batch. The training process tries to maximize the cosine similarity between the embeddings of the real pairs and minimize the similarity between the embeddings of the incorrect pairs. 
Figure 2: Contrastive pre-training.
By repeating this process several times for the entire dataset, CLIP manages to learn representations of many concepts. After training, the learned embeddings can be used for various purposes. CLIP can be used for the aforementioned classification of images, but there are other interesting use cases where the qualities of CLIP come into their own.
Use cases: What is CLIP used for?
CLIP was originally developed for image classification, but is now used for many more applications:
- Multimodality in LLMs: The ability to combine text and images also makes the use of CLIP models in LLMs interesting. For example, they can be used for Visual Question Answering, where questions about images are answered, or for multimodal translation, such as describing an image of the user.
- Semantic search system: Image search engines often rely on human manual tagging and metadata, which is a lot of work and prone to error. CLIP translates textual searches directly into relevant images without the need for manual tagging.
- Content moderation: CLIP’s versatility also makes it a good tool for keeping content in online communities safe. CLIP can detect and automatically remove undesirable content such as nudity, weapons or drugs. Thanks to its flexibility, additional categories can be easily added without re-training the model.
- Accessibility: Blind and visually impaired people online rely on a screen reader to tell them what is on a Web page. For these screen readers, it is important that images have alt text describing what is in an image. Unfortunately, this alt text is not always present. In these cases, CLIP could be used to automatically generate a description of an image.
- Recommendation system: CLIP can match images without text. For example, a user of an online store can upload a picture of a sofa, and the system will recommend similar products.
- Generative models: Generative models such as[DALL-E] and[Stable Diffusion] use CLIP under the hood to convert the user’s prompt to usable numerical input for a generative model.
The future of CLIP
CLIP is a versatile solution to the problem of generalization in computer vision. Its ability to understand images and text opens the door to a variety of applications, from content moderation to improved accessibility, efficient recommendation systems and many more.
Moreover, its integration into modern LLMs such as GPT-4 shows that CLIP goes beyond computer vision alone. The technology makes AI even more flexible and powerful. And with the speed at which AI is evolving, this is just the beginning.


