

The first question you probably ask is: why?
A mortgage lender can explain for what reasons you do not meet the requirements to receive a mortgage.
But what if this decision is made by a machine learning model?
We don’t settle for “computer says no.” The lack of an explanation is problematic and affects several stakeholders.
For the person the decision is about, it is important that the reasoning can be explained.
In doing so, you want to prevent the decision from being based on unintentional discrimination, for example: a person should not be rejected based on ethnicity.
For the data scientists and data engineers training a model, it is essential to understand the model’s behavior in order to detect any errors or weaknesses. eXplainable AI (XAI) can help improve a model.We are increasingly encountering automated systems that use machine learning algorithms.
These are being deployed in government agencies, finance and healthcare, among others.
And there is good reason for this.
In many cases, these algorithm perform well, sometimes even better than a person.
But can we blindly trust a model with an accuracy of 90% and higher, or should we ask ourselves how such an algorithm arrived at its decision?
In recent years, research on XAI has increased significantly.
More attention has arisen to ethics within Artificial Intelligence.
Possibly because AI is becoming more widely used and more frequently applied to important decisions, but also because algorithms are becoming increasingly complex.
Too complex to understand.
So is XAI the solution?
What is explainability?
Let’s start by defining the concept of explainability .
Unfortunately, there is no unambiguous explanation (yet).
The following definition is usually used in the literature: “the extent to which a human can understand the cause of a decision” [1].
This refers to a decision made by a machine learning model or algorithm.
We can generally distinguish between two types of explainability:
Ante-hoc explainability
Explainability by design.
In this case, a model is developed that is inherently transparent.
For example, consider a simple decision tree or a simple linear model.
These models are easy for people to understand and thus “explainable”; we can understand how they arrive at a decision.
Post-hoc explainability
But what do you do when a model is not transparent?
People call such a model a ‘black box,’ where only the inputs and outputs are transparent and we don’t know what happens inside.
In this case, you can opt for post-hoc explainability: we generate an explanation for a black box model that already exists and that itself is not “explainable.
To achieve this, another algorithm is often used to explain the original, black-box algorithm and break it open, so to speak.
Which is preferred?
A simple model that is already explainable is usually preferable to a complex neural network that still needs to be explained using post-hoc XAI techniques.
However, there are regular situations where a simpler model is not sufficient, and simply does not achieve the performance that a more complex model can.
Then you have to deal with the trade-off between accuracy and explainability: a trade-off must be made between the performance of a model and its explainability.
As illustrated in the figure below, higher explainability often comes at the expense of a model’s accuracy.
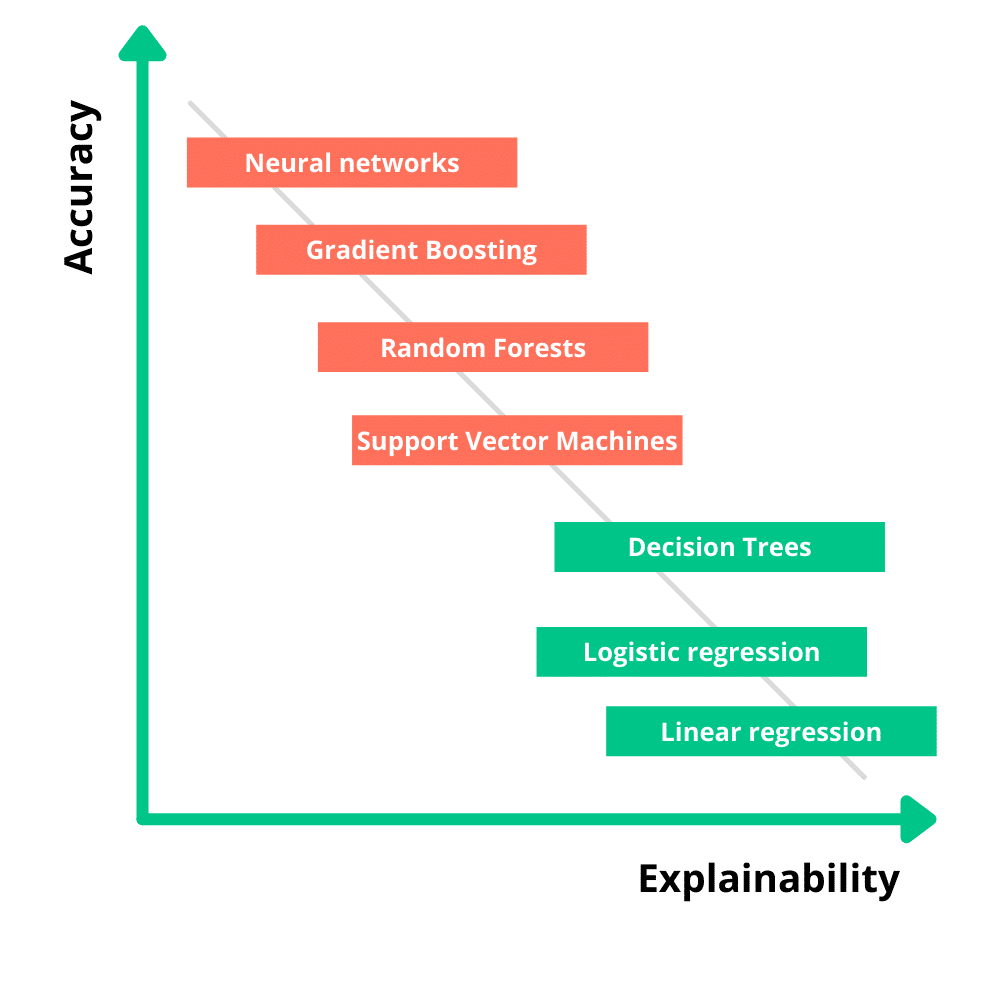
In this way, it is possible to use a black box neural network for a prediction task and explain the decisions afterwards without sacrificing power and performance.
Another advantage is that this technique can be applied to existing – and different types of – models.
This is often referred to as post-hoc explainability when talking about XAI.
Why is XAI important?
It is essential that the data scientists and data engineers understand what a model is doing in order to debug the model and counteract any unintended discrimination.
Before a model is put into production, it is important that people trust the model’s predictions.
But it is likely that an outcome will not be trusted if we do not understand it.
The lack of explainability may mean that the model will not be used by the end user.
A model that does explain the outcomes is transparent, which will increase trust in it.
Privacy legislation in the EU must also be taken into account.
Due to the requirements of the General Data Protection Regulation, it will be more difficult to implement a model in practice if it is not explainable.
Moreover, the European Commission is stepping it up with its recent proposal for an AI regulation; in fact, it was announced in April 2021 that we can expect stricter rules when it comes to high-risk AI applications.
How do we address this?
Many different methods for explaining machine learning models already exist.
And this number is growing considerably.
We can subdivide these methods by their explanation scope.
Global XAI methods try to explain the behavior of the entire model, while local XAI methods focus on explaining an individual decision.
Whereas a global explanation is mainly valuable for a data scientist, a local explanation is actually useful for the individual to whom a decision relates.
The two best-known examples of local (and post-hoc) methods are LIME (Local Interpretable Model-agnostic Explanations)[2] and SHAP (SHapley Additive exPlanations)[3].
These algorithms are somewhat different, but the idea is the same: It changes parts – or features – of the input data and looks at the degree of influence on the final decision.
For a mortgage application, it might change the amount of income, or, for example, whether or not a person has debt.
In the case of text classification, a number of words are replaced or removed, then the new outcome is determined.
In the case of an image, it is divided into super-pixels: groups of pixels with similar colors and brightness.
The result is a collection of scores that indicates how important each features is to the decision.
What such a LIME or SHAP explanation looks like depends on these features (which again depends on the type of data).
For tabular data, the features and their corresponding scores can be represented in a diagram: 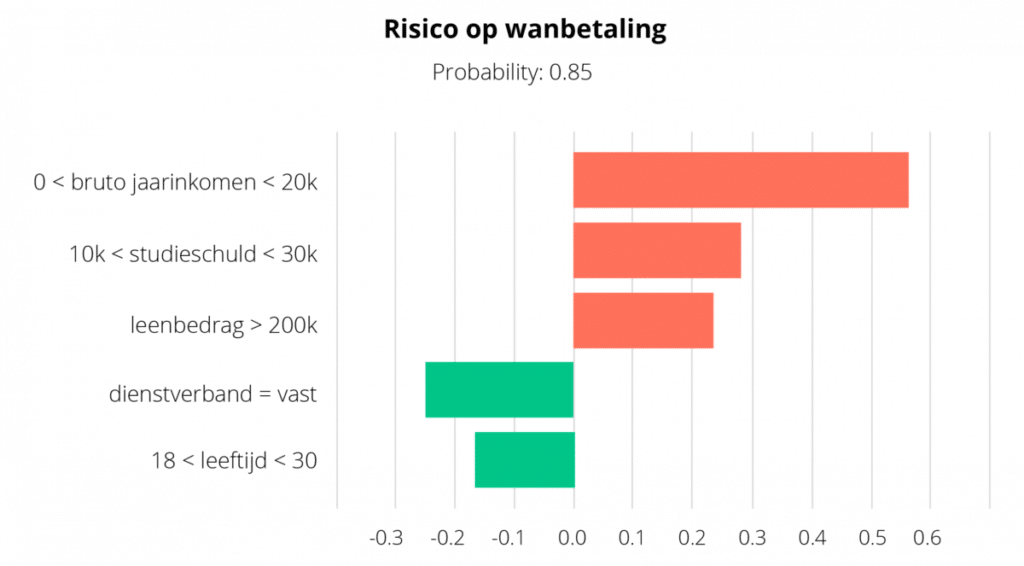
A fictitious example of a LIME explanation of a prediction of whether the mortgage applicant has a low/high risk of default.
Red indicates features that contribute to the outcome “high risk of default,” green “low risk of default.
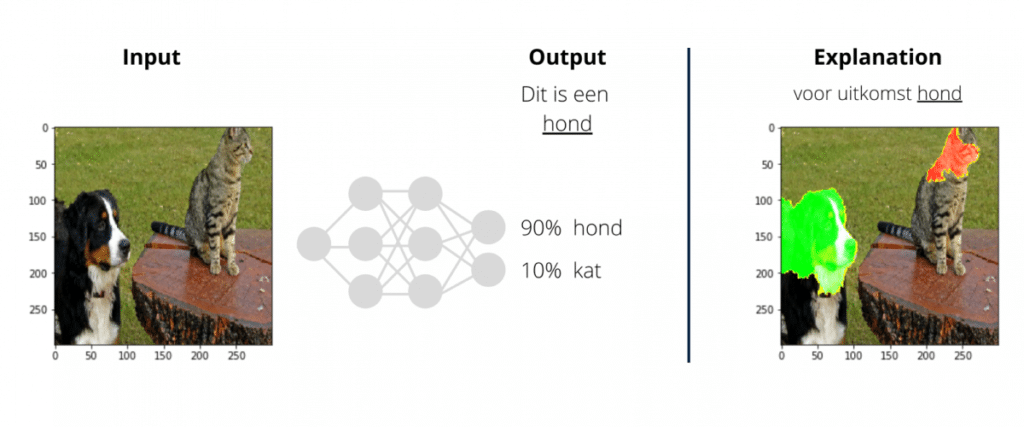
LIME’s software is accessible and applying it is not too complicated.
But more importantly, it considers each model as a black-box to which it has no access, meaning it can be applied to any model.
SHAP could also provide a solution.
It provides a more robust outcome in exchange for longer computation time.
This is in contrast to XAI methods that are model-specific and can only be applied to a specific type of model and cannot be implemented arbitrarily.
How to proceed?
We have a model whose decisions can be explained, but what follows?
Can we assume that the explanation from LIME is the correct one?
The answer is no.
Just as a prediction model must be evaluated, so must an explanation.
It is possible that the explanations generated by LIME look plausible to us, but do not actually reflect the behavior of the model.
There is also a reasonable chance that another XAI method, such as SHAP, will generate explanations that are different from LIME.
Evaluating explanations is a whole study in itself that is still the subject of much research.
Still, it makes sense to pay attention to the explainability of a model, especially if it involves a high-risk decision that has societal implications.
Think of systems in healthcare, government agencies or within education.
The degree of explainability required within these sectors will be higher than for systems such as spam filters, chatbots or recommendations.
Conclusion
With the increasing complexity of algorithms, it is becoming increasingly difficult to explain and understand exactly what they do.
Still, it is important to understand how a model arrived at a decision and what features are involved.
Explainability is important not only for data scientists and data engineers, but also for the end user, domain experts and everyone else involved.
It can ensure that trust in a system is increased, errors and weaknesses are detected and unfair situations are avoided.
Yet not all algorithms need the same degree of explainability.
For a medical diagnosis, explainability is essential, while for a personal Netflix recommendation it is not so necessary.
Does the performance of a model matter less and high explainability is paramount?
Then prefer a simpler model whose decision making is already transparent.
Be careful with XAI techniques such as LIME and SHAP; even though it can provide good insights, it is important to remember that different XAI techniques can generate different explanations for the same decision.
Therefore, do not hold a black box model as the final explanation for the decision made, but see it as a support system.
A “second opinion.
And leave the final decision of whether someone gets a mortgage to a human anyway.
http://arxiv.org/abs/1706.07269
[2] https://github.com/marcotcr/lime[3] https://github.com/slundberg/shap


