

Wat is explainability?
Laten we beginnen door het begrip explainability te definiëren. Een eenduidige uitleg is er helaas (nog) niet. In de literatuur wordt meestal de volgende definitie aangehouden: “de mate waarin een mens de oorzaak van een beslissing kan begrijpen” [1]. Het gaat hier om een beslissing die wordt gemaakt door een machine learning model of algoritme. We kunnen over het algemeen onderscheid maken tussen twee soorten explainability:
Ante-hoc explainability
Explainability by design. In dit geval wordt een model ontwikkeld dat van nature transparant is. Denk bijvoorbeeld aan een simpele beslisboom of een simpel lineair model. Deze modellen zijn makkelijk te begrijpen voor mensen en dus ‘explainable’; wij kunnen begrijpen hoe deze tot een beslissing komen.
Post-hoc explainability
Maar wat doe je wanneer een model niet transparant is? Men noemt zo’n model een ‘black box’, waarbij alleen de in- en output inzichtelijk is en we niet weten wat er van binnen gebeurt. In dit geval kun je kiezen voor post-hoc explainability: we genereren een uitleg voor een black box model dat al bestaat en dat zelf niet ‘explainable’ is. Om dit te bereiken wordt vaak een ander algoritme gebruikt om het originele, black-box algoritme te verklaren en als het ware open te breken.
Wat heeft de voorkeur?
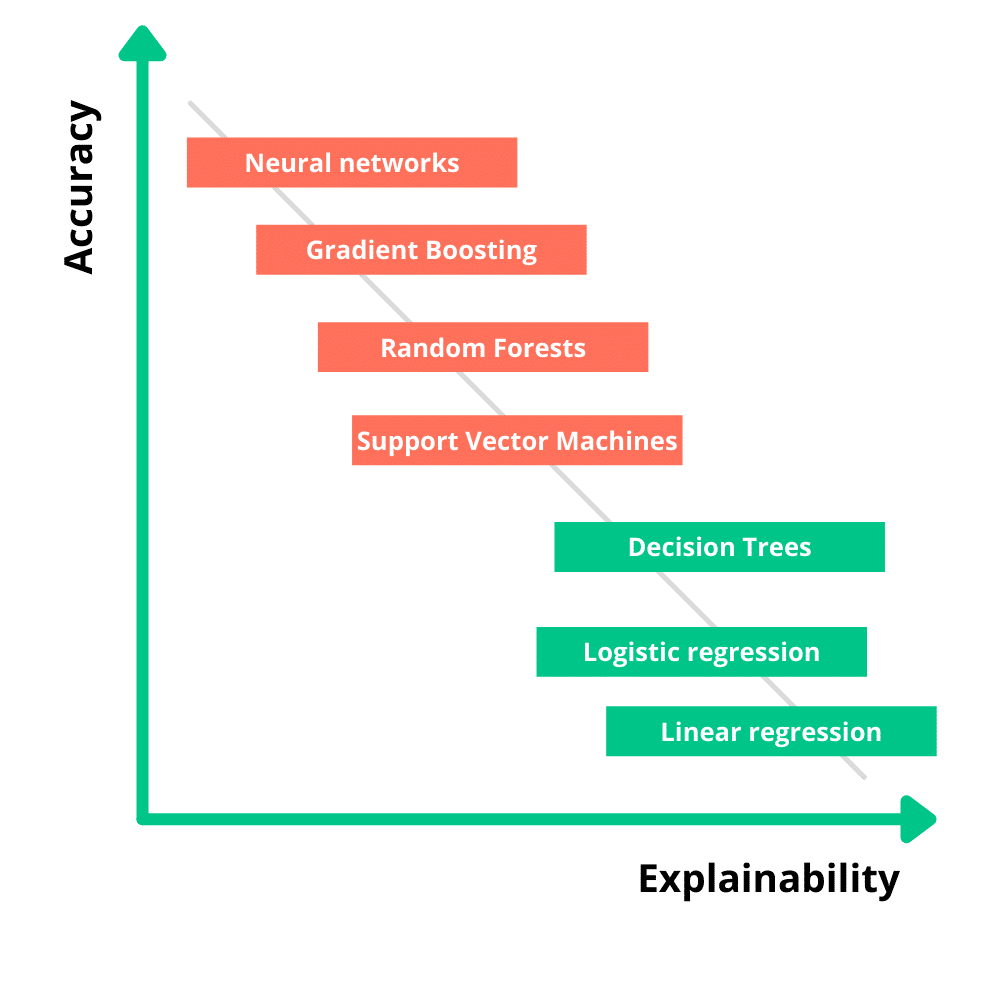
Een eenvoudig model dat al explainable is heeft meestal de voorkeur boven een complex neuraal netwerk dat nog uitgelegd moet worden met behulp van post-hoc XAI-technieken. Er zijn echter regelmatig situaties waarbij een eenvoudiger model niet volstaat, en simpelweg niet de prestaties behaalt die een complexer model wél kan bereiken. Dan krijg je te maken met de trade-off tussen accuracy en explainability: er moet een afweging worden gemaakt tussen de prestatie van een model en de uitlegbaarheid hiervan. Zoals in onderstaand figuur wordt afgebeeld, gaat een hogere explainability vaak ten koste van de nauwkeurigheid van een model.
Waarom is XAI belangrijk?
Het is essentieel dat de data scientists en data engineers begrijpen wat een model doet, om zo het model te kunnen debuggen en eventueel onbedoelde discriminatie tegen te gaan. Voordat een model in productie wordt gebracht is het belangrijk dat mensen vertrouwen hebben in de voorspellingen van het model. Maar het is aannemelijk dat een uitkomst niet wordt vertrouwd wanneer wij het niet begrijpen. Het gebrek aan explainability kan ertoe leiden dat het model niet zal worden gebruikt door de eindgebruiker. Een model dat de uitkomsten wél kan uitleggen is transparant, waardoor het vertrouwen hierin zal toenemen.
Daarnaast moet rekening gehouden worden met de privacywetgeving in de EU. Door de eisen uit de Algemene Verordening Gegevensbescherming zal het moeilijker zijn om een model te implementeren in de praktijk als het niet uitlegbaar is. Bovendien doet de Europese Commissie er een schepje bovenop door haar recente voorstel voor een AI-verordening; in april 2021 is namelijk bekend gemaakt dat we strengere regels kunnen verwachten als het gaat om risicovolle AI-toepassingen.
Hoe pakken we dit aan?
Er bestaan inmiddels al veel verschillende methoden voor het uitleggen van machine learning modellen. En dit aantal groeit aanzienlijk. Deze methoden kunnen we onderverdelen door middel van hun explanation scope. Globale XAI-methoden proberen het gedrag van het gehele model te verklaren, terwijl lokale XAI-methoden zich focussen op het verklaren van een individuele beslissing. Waar een globale uitleg voornamelijk waardevol is voor een data scientist, is een lokale uitleg juist nuttig voor de persoon waar een beslissing betrekking op heeft.
De twee bekendste voorbeelden van lokale (en post-hoc) methodes zijn LIME (Local Interpretable Model-agnostic Explanations)[2] en SHAP (SHapley Additive exPlanations)[3]. Deze algoritmes zijn wat verschillend, maar het idee is hetzelfde: het verandert delen - of features - van de input data en kijkt naar de mate van invloed op de uiteindelijke beslissing.
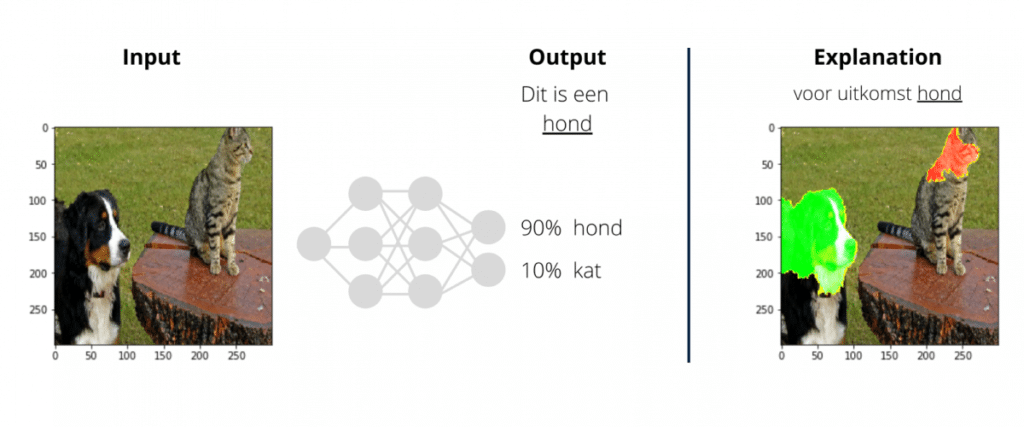
Voor een hypotheekaanvraag kan de hoogte van het inkomen worden aangepast, of bijvoorbeeld het wel of niet hebben van een schuld. In het geval van tekstclassificatie worden een aantal woorden vervangen of weggehaald, waarna de nieuwe uitkomst wordt bepaald. In het geval van een afbeelding wordt deze opgedeeld in super-pixels: groepen pixels met vergelijkbare kleuren en helderheid. Het resultaat is een verzameling van scores dat aangeeft hoe belangrijk elke features is voor de beslissing.
Hoe zo’n LIME of SHAP explanation eruitziet hangt af van deze features (wat ook weer afhankelijk is van het type data). Voor tabulaire data kunnen de features en hun bijbehorende scores worden weergegeven in een diagram:
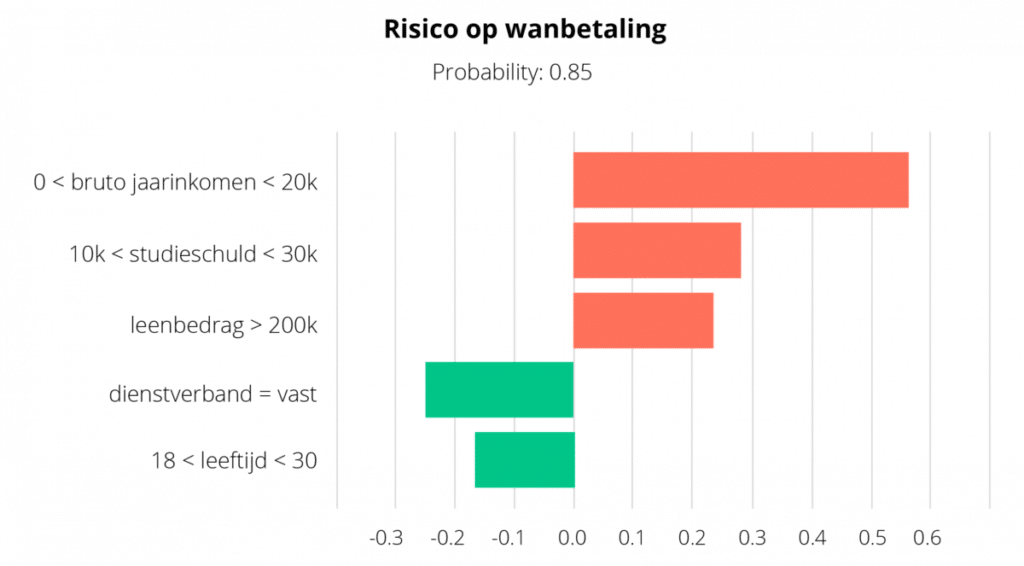
Een fictief voorbeeld van een LIME uitleg van een voorspelling of de hypotheekaanvrager een laag/hoog risico heeft op wanbetaling. Met rood worden de features aangegeven die bijdragen aan de uitkomst ‘hoog risico op wanbetaling’, met groen ‘laag risico op wanbetaling’.
Hoe verder?
We hebben een model waarvan de beslissingen uitgelegd kunnen worden, maar wat volgt? Kunnen wij ervan uitgaan dat de uitleg vanuit LIME de juiste is? Het antwoord is nee. Net zoals dat een voorspelmodel geëvalueerd dient te worden, moet een uitleg dat ook. Het is mogelijk dat de explanations die LIME genereert er plausibel uitzien voor ons, maar eigenlijk niet het gedrag van het model weerspiegelen. Ook zit er een redelijke kans in dat een andere XAI-methode, zoals SHAP, een andere uitleg geeft dan LIME. Het evalueren van explanations is een hele studie op zich waar nog veel onderzoek naar wordt gedaan.
Toch is het zinvol om aandacht te besteden aan de explainability van een model, vooral als het gaat om een risicovolle beslissingen dat maatschappelijke implicaties heeft. Denk aan systemen in de zorg, bij overheidsinstellingen of binnen het onderwijs. De benodigde mate van explainability zal binnen deze sectoren hoger liggen dan bij systemen zoals spamfilters, chatbots of aanbevelingen.
Conclusie
Door de toenemende complexiteit van algoritmes, wordt het steeds lastiger uit te leggen en begrijpen wat ze precies doen. Toch is het belangrijk om te begrijpen hoe een model tot een beslissing is gekomen en welke features daarbij een rol spelen. Explainability is niet alleen belangrijk voor de data scientists en data engineers, maar ook voor de eindgebruiker, domeinexperts en alle andere betrokkenen. Het kan ervoor zorgen dat het vertrouwen in een systeem wordt vergroot, fouten en zwakheden worden ontdekt en oneerlijke situaties worden voorkomen. Toch hebben niet alle algoritmes dezelfde mate van explainability nodig. Voor een medische diagnose is een uitleg essentieel, terwijl dat voor een persoonlijke Netflix aanbeveling niet zo nodig is. Maakt de performance van een model minder uit en staat een hoge explainability voorop? Dan gaat de voorkeur uit naar een eenvoudiger model waarvan de besluitvorming al transparant is. Let wel op met XAI-technieken zoals LIME en SHAP; ondanks dat het goede inzichten kan geven is het belangrijk om te onthouden dat verschillende XAI-technieken verschillende explanations kunnen genereren voor dezelfde beslissing. Houd een black box model daarom niet als eindverantwoordelijke voor de gemaakte beslissing, maar zie het als een ondersteunend systeem. Een ‘second opinion’. En laat de uiteindelijke beslissing of iemand een hypotheek krijgt toch maar over aan een mens.
[2] https://github.com/marcotcr/lime
[3] https://github.com/slundberg/shap


