
Summary
Any Data Scientist is probably familiar with pandas and scikit-learn.
The usual workflow starts with data cleaning in pandas, further preprocessing using pandas or scikit-learn transformers like StandardScaler, OneHotEncoder etc., then you start working with a machine learning algorithm (scikit-learn).
Now there are some problems with this workflow:
1. The development phase in your workflow is quite complex and requires a lot of code ? 2. It is difficult to reproduce workflow for forecasting in the implementation phase ? 3. Existing solutions to reduce these problems are not good enough (yet) ? Skippa is a package designed to:
- ✨ drastically simplify development
- ?
pack all data cleaning and pre-processing along with the algorithm into a single pipeline file - ?
reuse the interface from pandas and scikit-learn, which you are already familiar with”
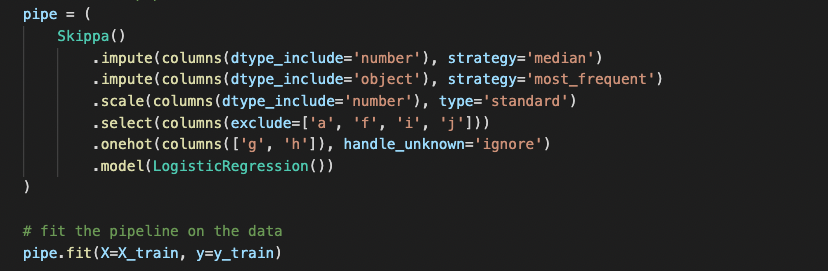
Skippa helps you easily define data cleaning and pre-processing transformations.
It works roughly as follows:
from skippa import Skippa, columns from sklearn.linear_model import LogisticRegression X, y = get_training_data(...) pipeline = ( Skippa() .impute(columns(dtype_include='object'), strategy='most_frequent') .impute(columns(dtype_include='number'), strategy='median') .scale(columns(dtype_include='number'), type='standard') .onehot(columns(['category1', 'category2'])) .model(LogisticRegression()) ) pipeline.fit(X, y) predictions = pipeline.predict_proba(X)
☝️Skippa does not presume to solve all problems, does not cover all the functionality you might ever need, and is not a highly scalable solution, but it should be able to provide a huge simplification for > 80% of regular pandas/sklearn-based machine learning projects.
Links
You can read the rest of the blog here > Introduction Skippa [ENG]


