
Samenvatting
Elke Data Scientist is waarschijnlijk bekend met pandas en scikit-learn. De gebruikelijke workflow begint bij het opschonen van gegevens in pandas, verdere voorbewerking met behulp van pandas of scikit-learn transformers zoals StandardScaler, OneHotEncoder etc., daarna ga je aan de slag met een machine learning-algoritme (scikit-learn).
Nu zijn er enkele problemen met deze workflow:
1. De ontwikkelfase in je workflow is nogal complex en vereist veel code ?
2. Het is moeilijk om de workflow te reproduceren voor voorspellingen in de implementatiefase ?
3. Bestaande oplossingen om deze problemen te verminderen zijn (nog) niet goed genoeg ?
Skippa is een package die ontworpen is om:
- ✨ drastisch de ontwikkeling te vereenvoudigen
- ? alle data cleaning en pre-processing samen met het algoritme in één enkel pipeline bestand te verpakken
- ? de interface te hergebruiken van pandas en scikit-learn, waar je al bekend mee bent"
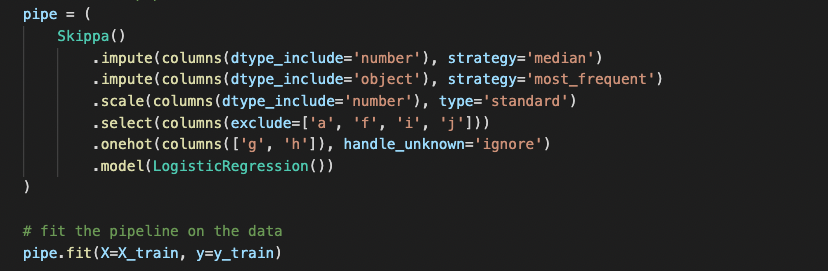
Skippa helpt je bij het eenvoudig definiëren van data cleaning en pre-processing transformaties. Het werkt ongeveer als volgt:
from skippa import Skippa, columns from sklearn.linear_model import LogisticRegression X, y = get_training_data(...) pipeline = ( Skippa() .impute(columns(dtype_include='object'), strategy='most_frequent') .impute(columns(dtype_include='number'), strategy='median') .scale(columns(dtype_include='number'), type='standard') .onehot(columns(['category1', 'category2'])) .model(LogisticRegression()) ) pipeline.fit(X, y) predictions = pipeline.predict_proba(X)
☝️Skippa veronderstelt niet alle problemen op te lossen, dekt niet alle functionaliteit die je ooit nodig zou kunnen hebben en is geen zeer schaalbare oplossing, maar het zou een enorme vereenvoudiging moeten kunnen bieden voor > 80% van de reguliere op pandas/sklearn gebaseerde machine learning-projecten.


