
The second part looks at concrete applications and specific possibilities with Dutch text.
Conceptually since the 1950s and practically since say the 1990s.
Topics such as Named Entity Recognition, Part-of-Speech tagging, mood & lemmatization are standard parts of NLP toolkits.
The main problems for which text data is applied are semantic search, sentiment analysis, topic modeling, classification, clustering.
Common techniques here are bag-of-words, tf-idf, Naïve Bayes, LDA.What we do see in recent years is a shift away from NLP techniques based on neural networks.
This started with the introduction of word2vec[1] in 2013: a kind of dictionary that allows you to translate a word into a series of numbers with a semantic payload (word embeddings).
These embeddings were widely used in recurrent neural networks.
The principle of attention[2] made neural networks better able to learn a memory for longer-term relationships within pieces of text.
With the advent of the transformer[3], this was further greatly improved and today everything revolves around pre-trained language models from the BERT family[4]. With this, transfer learning has finally become a reality within NLP, just as pre-trained convolutional neural networks previously were within Computer Vision.
Chronologically, then, the most important developments in the academic sense are:

Why is this so important?
Because it dramatically changes the way text is represented.
Representations for text data
A computer cannot do math with text.
Only with numbers.
If we want to unleash algorithms on text data, we will first have to “translate” this text into numbers.
In other words, find a numerical representation.

Bag-of-words
For many years, the bag-of-words (BoW) representation has mostly been used.
This approach is simple.
Suppose you have a set of documents (pieces of text).
The approach then is:
- See which words occur
- Set up a dictionary with that
- For each document: count the number of occurrences of each word in the dictionary
- Each document is now a long string of numbers
- Your ‘corpus’ (text dataset) is now an array of numbers
- B. Often stop words are filtered out of the dictionary
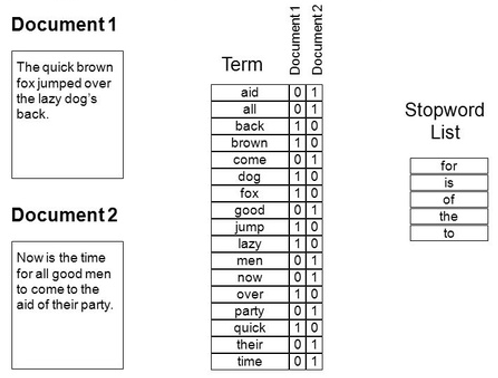
Often tf/idf is still used to give distinctive words a higher weighting score in this matrix and irrelevant words a lower score, but this technique is not exclusively tied to BoW.But what is the problem with this representation?
The simplicity of BoW is its strength, but there are also some limitations.
To understand text, we need:
- Understanding the meaning of single words
- Understanding the relationship between words
How does BoW score on this?
- Understanding the meaning of single words
- A word is represented only by an index referring to the dictionary.
No meaning is attached to it.
- A word is represented only by an index referring to the dictionary.
- Understanding the relationship between words
- The order of the words in the text is ignored.
Two examples for clarification:
- BoW sees no similarity between ‘animal’ and ‘beast,’ even though they are virtually identical
- In contrast, BoW sees these sentences as exactly the same:
- “Not as I expected, this movie is great”
- “As I expected, this movie is not great”
Word embeddings
The core idea underlying word embeddings is John Firth’s distributional hypothesis[5]: “You shall know a word by the company it keeps.”
Paraphrased, this means: the meaning of a word can be derived from the context in which it appears.
And that indicates exactly how the word2vec algorithm works: start looking in pieces of text to see which words occur among which context words.

This gives you a lot of data on which you can train a model (neural network) that – given a word – tries to predict the context words.
This seems like a useless and unhelpful task, but the advantage of this is that as a by-product you get a matrix with a set of weights (numbers) for each word.
And the beauty here is: there is something special about these numbers.
Namely, it turns out that the meaning of the word is actually hidden in these numbers and can actually be extracted from them!
How?
By comparing numbers: numbers can be close together (81 and 82) or far apart (2 and 81), which you can interpret as similar or not similar.
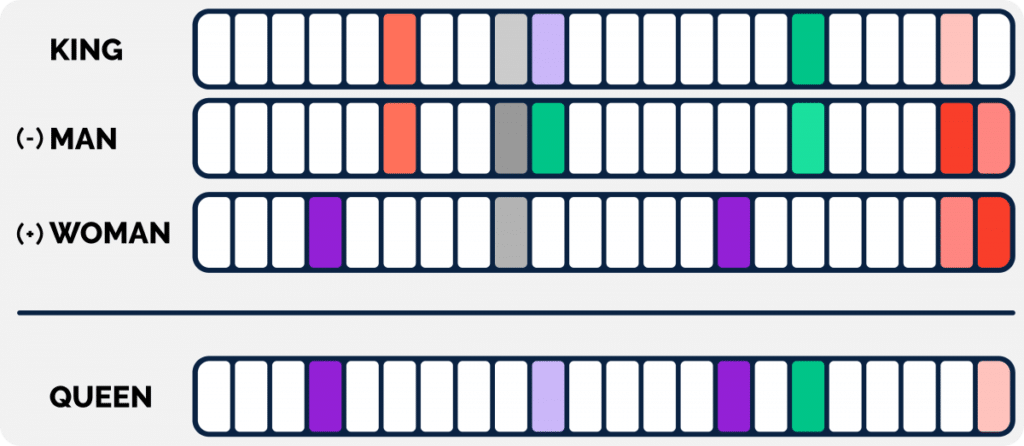
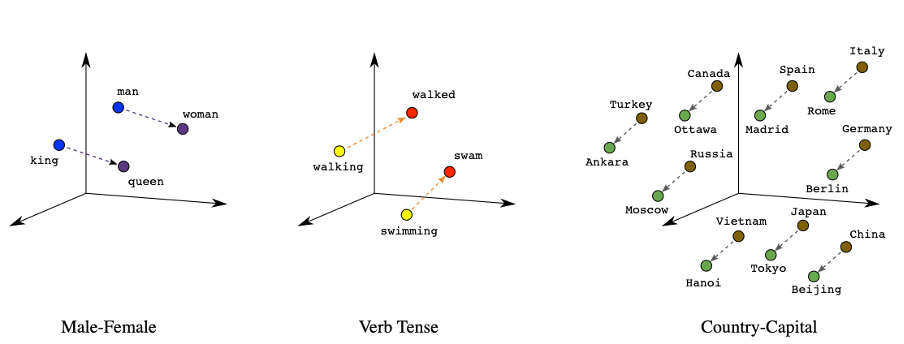
And since each word consists of several numbers there are several forms of similarity to consider.An example: the now canonical “king – man + woman = queen”: Let’s take a look at the obtained numbers (we thus call these embeddings) of the four words “king”, “man”, “woman” and “queen” in the picture below.
Here the following stands out:
- Some numbers/columns (shown below with color) are close to each other, if we compare “king” and “man.”
This suggests that there should be a semantic similarity between these two words (which there is) - Ditto for “woman” and “queen”
- A similar resemblance exists between “king” and “queen,” but with different numbers/columns
Word embeddings as transfer learning
Now where do you get these word embeddings?
Generally, you don’t create them yourself, you reuse existing ones.
Researchers at Google have trained their word2vec algorithm on huge datasets and made the embeddings publicly available, in several languages.
By the way, there are other algorithms for creating word embeddings.
The best known are fastText from Facebook and GloVe from Stanford.
All of these can be downloaded and used.
The first form of transfer learning within NLP.
From word embeddings to text embeddings
So, we have found a new representation for words where the meaning is more or less encoded in the numbers.
How can we evaluate this representation?
- Understanding the meaning of single words
- This now seems to have worked out excellently!
The word embeddings of “animal” and “beast” will be very similar
- This now seems to have worked out excellently!
- Understanding the relationship between words
- Um, the consistency…?
Well, word embeddings are, as the term implies, representations of words, but not yet of sentences or pieces of text.
At least with BoW, we could represent pieces of text, but how to proceed?
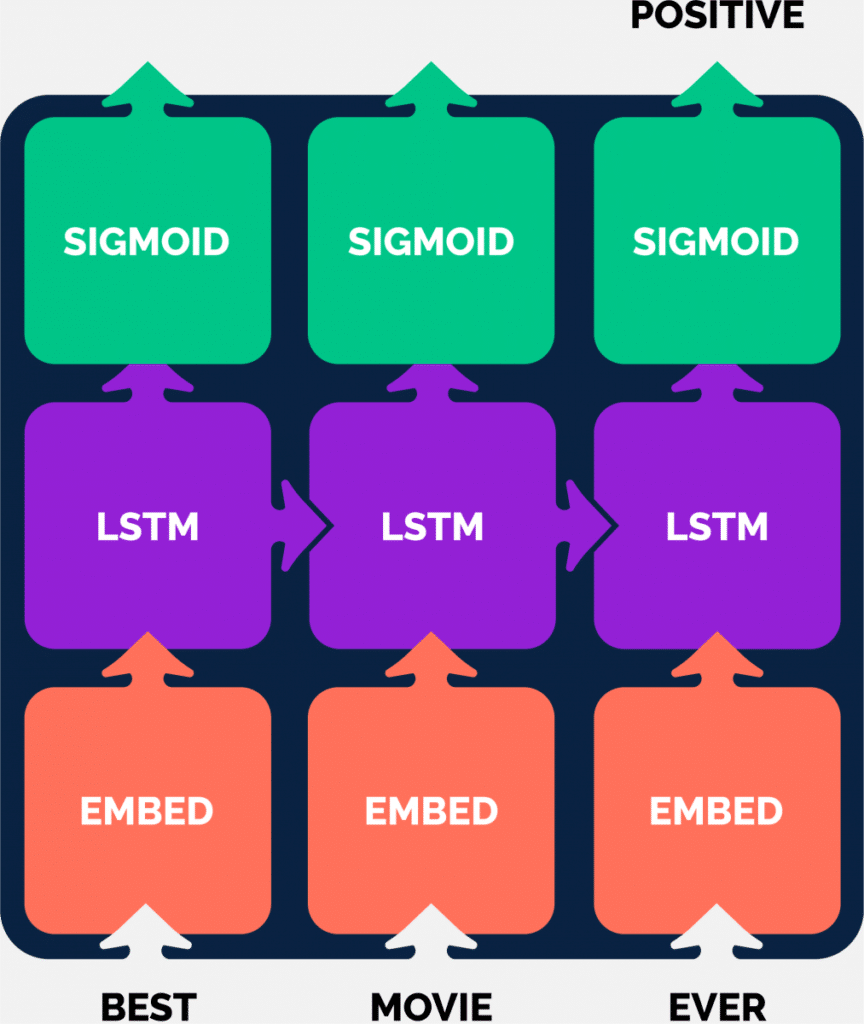
A commonly used method was to use recurrent neural networks (e.g. LSTM, GRU) i.c.w. word embeddings.
Here a text is broken down into words and translated into a series of word embeddings, which are read in step by step.
At each step, the internal “memory” of the network is updated, so you still get an embedding of the entire text.
This embedding is then used for the corresponding task (predicting, generating text, etc.).
- ‘direct’ text embedding techniques
- improvements focused on context sensitivity
Direct text embeddings
There are several techniques for obtaining text embeddings.
Generally, these are used for embedding sentences or paragraphs.
Embedding whole pages of text at once will still not work well.
The simplest method (but not necessarily the worst) is to use average word embeddings: take the word embeddings of all the words in your piece of text and average them.
This has the disadvantage that it ignores the order of words and includes irrelevant words, but the latter can still be remedied by, for example, weighing the words beforehand with tf/idf and thus taking a weighted average.
A series of other attempts followed later.
The algorithm of doc2vec[6] is as it were an extension of word2vec, where the text is included as context in addition to the individual words.
Words and texts are thus encoded in the same embedding space and are mutually comparable.
In skip-thought vectors[7], the word2vec algorithm is scaled up in the sense that words are replaced by sentences.
Thus, from: “the meaning of a word is: the words between which it occurs”, to: “the meaning of a sentence is: the sentences between which it occurs”.
This is then done using RNNs (GRU) with word embeddings in an encoder-decoder model.
Context Sensitivity
Another movement focused more on getting neural networks to better handle context with word embeddings.
The concept of attention began as a technique for focusing attention on certain parts of the text during a given task.
Within the big picture (the whole text), a specific selection of the text (context) is relevant at certain times.
With the advent of the transformer architecture, all previous architectures based on recurrent and convolutional neural networks were replaced by a composition of different attention mechanisms.
The sequel was a series of large-scale language models based on transformers.
The best known, models from the BERT family, provide pre-trained context-sensitive word embeddings.
From here it is a relatively small step to text embeddings.
Sentence-BERT[8] (better known by the term sentence transformers) is a nice application-oriented implementation of this.
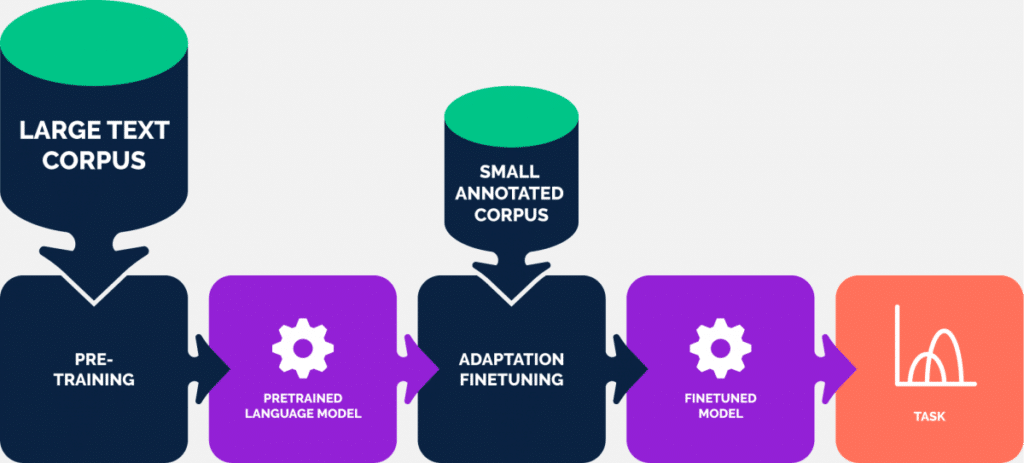
Here we have arrived at a significant point where transfer learning from NLP is finally a reality!
Wrap up
Now that we have arrived at these text embeddings, we have found a way to find a powerful representation for a piece of text that has managed to capture both the meaning of the words and the connections between them (the sentence structure).
So all we have to do is download a pre-trained model, generate embeddings for our text with it, and we’re good to go?
Depending on the task, this is true to some extent.
At least: in theory. In Part 2, we will see to what extent these promises are fulfilled in practice….


