


Representaties voor tekstdata
Een computer kan niet rekenen met tekst. Alleen met getallen. Als we algoritmes willen loslaten op tekstdata dan zullen we deze tekst eerst moeten ‘vertalen’ naar getallen. Met andere woorden: een numerieke representatie vinden.

Bag-of-words
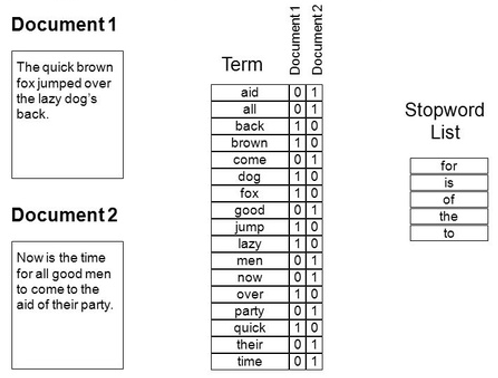
Sinds jaar en dag wordt veelal de bag-of-words (BoW) representatie gebruikt. Deze aanpak is simpel. Stel je hebt een set documenten (stukken tekst). De aanpak is dan:
- Kijk welke woorden voorkomen
- Stel daarmee een woordenboek op
- Voor elk document: tel het aantal voorkomens van elk woord in het woordenboek
- Elk document is nu een lange reeks getallen
- Je ‘corpus’ (tekst dataset) is nu een matrix van getallen
- B. Vaak worden stopwoorden uit het woordenboek gefilterd
- De betekenis van losse woorden begrijpen
- De samenhang tussen woorden begrijpen
Hoe scoort BoW hierop?
- De betekenis van losse woorden begrijpen
- Een woord wordt slechts gerepresenteerd door een index refererend aan het woordenboek. Er is geen enkele betekenis aan gekoppeld.
- De samenhang tussen woorden begrijpen
- De volgorde van de woorden in de tekst wordt genegeerd.
Twee voorbeelden ter verduidelijking:
- BoW ziet geen enkele overeenkomst tussen ‘dier’ en ‘beest’, terwijl ze vrijwel identiek zijn
- BoW ziet deze zinnen daarentegen als exact hetzelfde:
- “Niet zoals ik had verwacht, deze film is geweldig”
- “Zoals ik had verwacht, deze film is niet geweldig”
Word embeddings
Het kernidee dat ten grondslag ligt aan word embeddings, is de distributional hypothesis[5] van John Firth:
“You shall know a word by the company it keeps”.
Geparafraseerd betekent dit: de betekenis van een woord kan worden afgeleid uit de context waarin het voorkomt. En dat geeft precies aan hoe het word2vec-algoritme werkt: ga kijken in stukken tekst welke woorden voorkomen tussen welke contextwoorden.

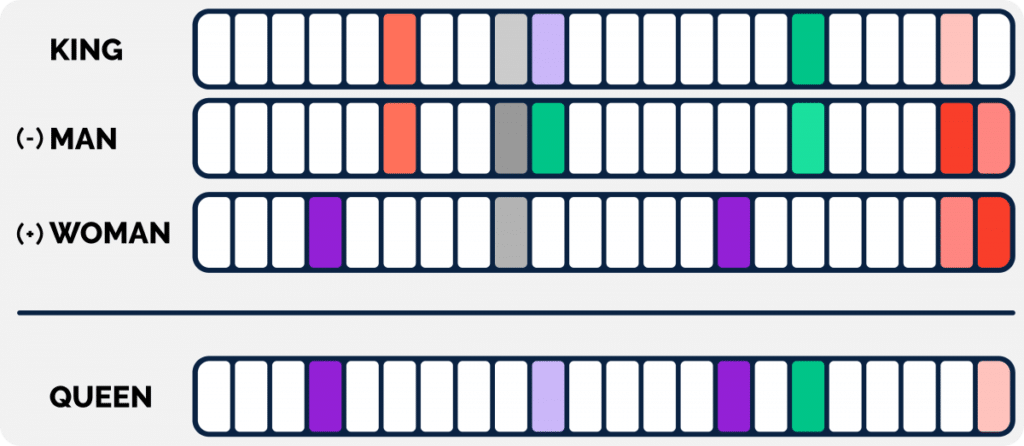
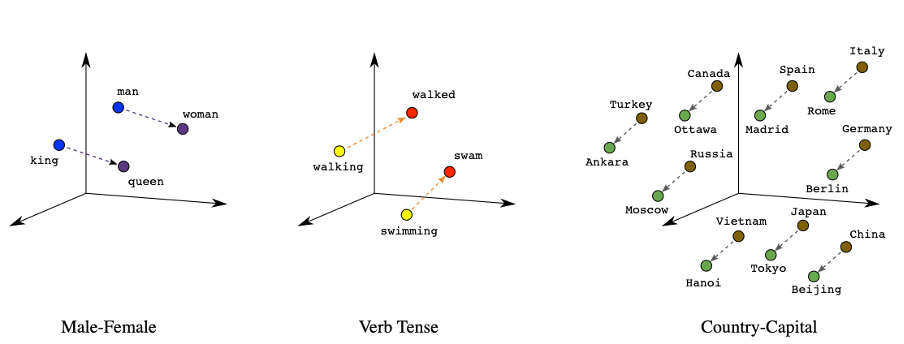
Laten we eens kijken naar de verkregen getallen (deze noemen we dus embeddings) van de vier woorden “king”, “man”, “woman” en “queen” in onderstaand plaatje.
Hierbij valt het volgende op:
- Sommige getallen/kolommen (hieronder weergegeven met kleur) liggen dicht bij elkaar, als we “king” en “man” vergelijken. Dat suggereert dat er een semantische gelijkenis zou moeten zijn tussen deze twee woorden (wat ook zo is)
- Idem voor “woman” en “queen”
- Een soortgelijke gelijkenis is er tussen “king” en “queen”, maar dan bij andere getallen/kolommen
Word embeddings als transfer learning
Hoe kom je nu aan die word embeddings? Over het algemeen maak je die niet zelf, maar hergebruik je bestaande. Researchers van Google hebben hun word2vec algoritme getraind op gigantische datasets en de embeddings publiek beschikbaar gemaakt, in verschillende talen. Overigens zijn er ook andere algoritmes om word embeddings te maken. De bekendste zijn fastText van Facebook en GloVe van Stanford. Deze kun je allemaal downloaden en gebruiken. De eerste vorm van transfer learning binnen NLP.
Van word embeddings naar text embeddings
Dus, we hebben een nieuwe representatie gevonden voor woorden waarbij de betekenis min of meer in de getallen ge-encodeerd is. Hoe kunnen we deze representatie beoordelen?
- De betekenis van losse woorden begrijpen
- Dit lijkt nu uitstekend gelukt! De word embeddings van “dier” en “beest” zullen erg op elkaar lijken
- De samenhang tussen woorden begrijpen
- Ehm, de samenhang…?
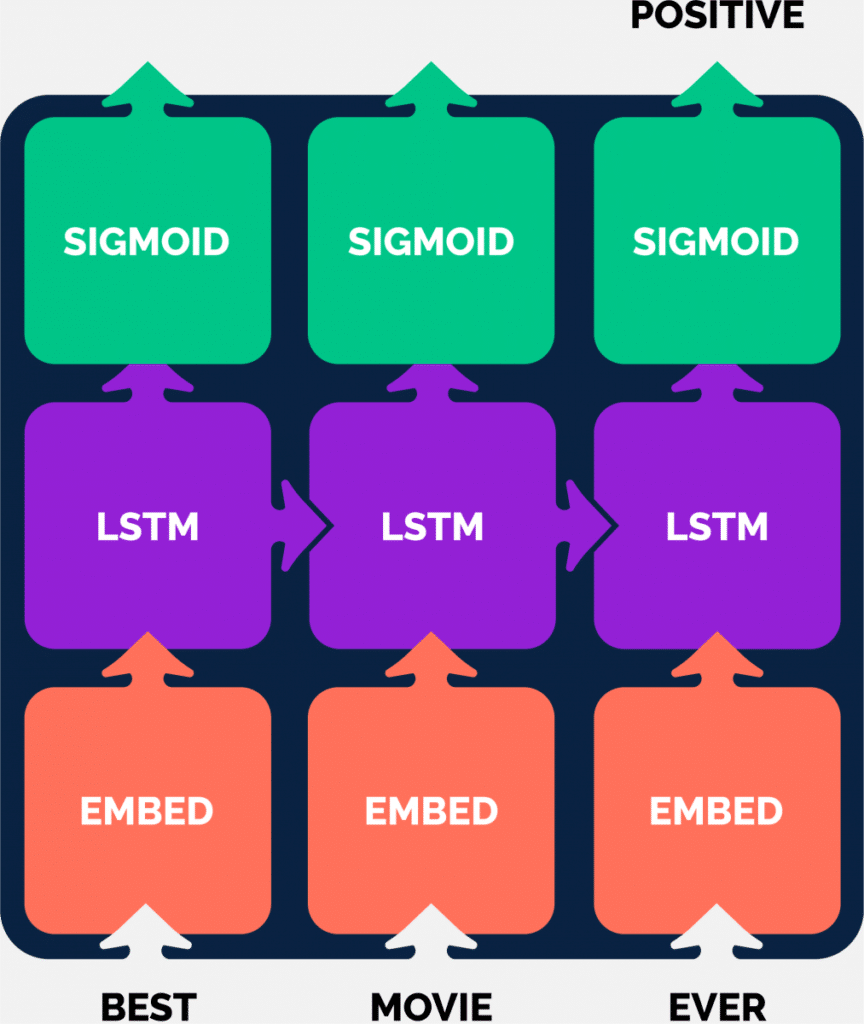
Tsja, word embeddings zijn, zoals de term al zegt, representaties van woorden, maar nog niet van zinnen of stukken tekst. Met BoW konden we ten minste wel stukken tekst representeren, maar hoe nu verder? Een vaak gebruikte methode was recurrent neural networks (bijv. LSTM, GRU) gebruiken i.c.m. word embeddings. Hierbij wordt een tekst opgesplitst in woorden en vertaald naar een reeks word embeddings, die stap voor stap worden ingelezen. In elke stap wordt het interne ‘geheugen’ van het netwerk bijgewerkt, zodat je alsnog een embedding krijgt van de hele tekst. Deze embedding wordt vervolgens gebruikt voor de desbetreffende taak (voorspellen, tekst genereren etc.).
- ‘directe’ text embedding technieken
- verbeteringen gericht op contextgevoeligheid
Directe text embeddings
Er zijn verschillende technieken om text embeddings te verkrijgen. Over het algemeen worden deze gebruikt voor het embedden van zinnen of alinea’s. Hele pagina’s tekst in een keer embedden zal nog niet goed werken. De meest eenvoudige methode (maar niet per se de slechtste) is het gebruik van average word embeddings: neem de word embeddings van alle woorden in je stuk tekst en neem daar het gemiddelde van. Dit heeft als nadeel dat het de volgorde van woorden negeert en irrelevante woorden meeneemt, maar dit laatste is nog te verhelpen door bijvoorbeeld de woorden vooraf te wegen met tf/idf en zo een gewogen gemiddelde te nemen. Later volgde een reeks andere pogingen. Het algoritme van doc2vec[6] is als het ware een uitbreiding van word2vec, waarbij de tekst als context meegegeven wordt naast de losse woorden. Woorden en teksten worden zo in dezelfde embedding space ge-encodeerd en zijn onderling vergelijkbaar. Bij skip-thought vectors[7] wordt het word2vec-algoritme opgeschaald in de zin dat woorden worden vervangen door zinnen.
Dus van: “de betekenis van een woord is: de woorden waartussen het voorkomt”, naar: “de betekenis van een zin is: de zinnen waartussen het voorkomt”. Dit wordt dan wel gedaan aan de hand van RNN’s (GRU) met word embeddings in een encoder-decoder-model.
Contextgevoeligheid
Een andere stroming was er meer op gericht om neurale netwerken met word embeddings beter met context om te kunnen laten gaan. Het begrip attention begon als techniek om tijdens een bepaalde taak de aandacht te leggen op bepaalde delen van de tekst. Binnen het grote geheel (de hele tekst) is op bepaalde momenten een specifieke selectie van de tekst (context) relevant. Met de komst van de transformer-architectuur werden alle eerdere architecturen gebaseerd op recurrent en convolutional neural networks vervangen door een samenstelling van verschillende attention-mechanismes. Het vervolg was een reeks grootschalige language models, gebaseerd op transformers. De bekendste, modellen uit de BERT-familie, bieden voorgetrainde context-gevoelige word embeddings. Vanaf hier is het een relatief kleine stap om tot text embeddings te komen. Sentence-BERT[8] (beter bekend onder de term sentence transformers) is een mooie toepassingsgerichte implementatie hiervan. Hier zijn we aangekomen op een significant punt waarbij transfer learning van NLP eindelijk een feit is!
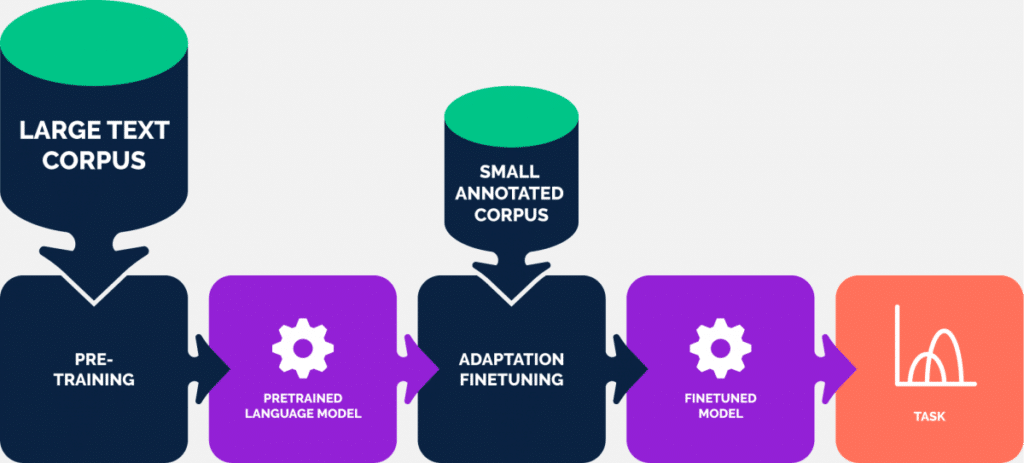
Wrap up
Nu we zijn aangekomen bij deze text embeddings hebben we een manier gevonden om een krachtige representatie te vinden voor een stuk tekst, die zowel de betekenis van de woorden als de verbanden tussen de woorden (de zinsopbouw) heeft weten te vangen. Dus het enige wat we hoeven te doen is een voorgetraind model downloaden, daarmee embeddings genereren voor onze tekst en we kunnen los? Afhankelijk van de taak is dat in zekere zin waar. Althans: in theorie.
In deel 2 gaan we zien in hoeverre deze beloftes worden waargemaakt in de praktijk…
[2] [Bahdanau et al. 2014] https://arxiv.org/abs/1409.0473
[3] [Vaswani et al. 2017] https://arxiv.org/abs/1706.03762
[4] [Devlin et al. 2018] https://arxiv.org/abs/1810.04805
[5] https://en.wikipedia.org/wiki/Distributional_semantics
[6] [Le, Mikolov 2014] https://arxiv.org/abs/1405.4053
[7] [Kiros et al. 2015] https://arxiv.org/abs/1506.06726
[8] [Reimers, Gurevych 2019] https://arxiv.org/abs/1908.10084


