

DeepSeek heeft zich op spectaculaire wijze gepositioneerd als een geduchte concurrent in de wereld van Large Language Models (LLMs). Met beurskoersen die schommelden en politieke spanningen die oplaaiden, kon je de afgelopen weken nauwelijks om DeepSeek heen. Maar wat maakt dit model zo bijzonder? Is het werkelijk revolutionair, of simpelweg een budgetvriendelijke variant van marktleiders zoals OpenAI’s ChatGPT? In deze blog gaan we in op de technische architectuur van DeepSeek en analyseren we waarom deze modellen zo efficiënt en snel zijn.
DeepSeek vs. marktleiders
Terwijl marktleiders zoals OpenAI, Meta en Google tientallen miljarden steken in de ontwikkeling van LLMs, beweert DeepSeek dat het zijn nieuwste model heeft getraind voor slechts een paar miljoen. En toch weet het de prestaties van deze gevestigde namen verrassend dicht te benaderen. DeepSeek heeft hiermee een indrukwekkende combinatie bereikt: de kracht en nauwkeurigheid van toonaangevende AI-modellen, zoals de OpenAI-o1, maar dan met een opmerkelijke efficiëntie en schaalbaarheid. Zo’n balans tussen prestaties en kostenbesparing hebben we niet eerder op deze schaal gezien.
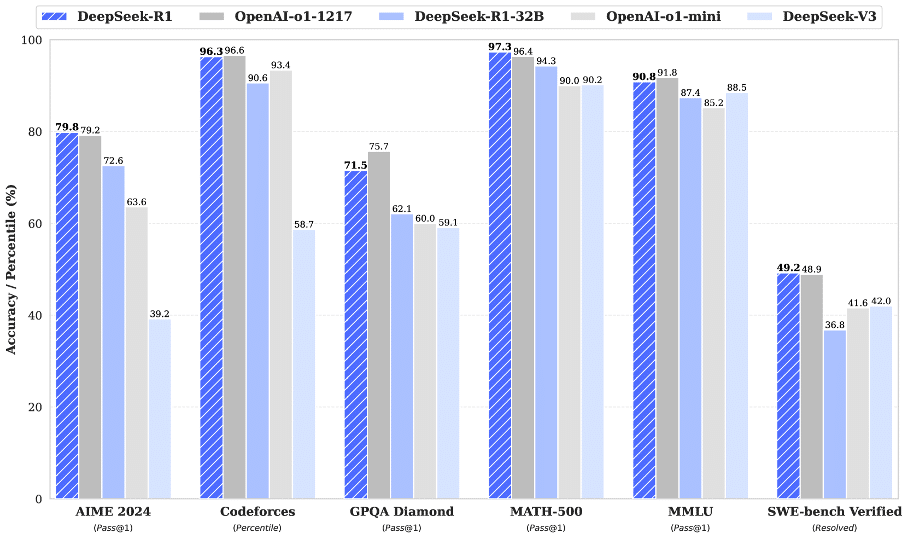
Figuur 1: Benchmark performance van DeepSeek-R1. (DeepSeek-R1)
Hoe werkt DeepSeek?
Om te begrijpen waarom DeepSeek zo snel en efficiënt is, duiken we in de onderliggende architectuur. Net als de meeste geavanceerde LLMs is DeepSeek gebaseerd op de Transformer-architectuur (Vaswani et al., 2017). Maar waar conventionele AI-modellen iedere neuron/parameter in het netwerk activeren bij elke input, pakt DeepSeek het anders aan met een Mixture-of-Experts (MoE) architectuur. Hierbij wordt slechts een kleine selectie gespecialiseerde subnetwerken - de ‘experts’- geactiveerd per input. Welke experts geselecteerd worden hangt af van hun relevantie voor de huidige input.
Dit innovatieve mechanisme vermindert drastisch de benodigde rekenkracht en verhoogt de snelheid van het model, zonder in te leveren op prestaties. Zo bevat DeepSeek-V3 bijvoorbeeld 671 miljard parameters, maar activeert het er per token slechts 37 miljard – slechts 18% van het totale model.
DeepSeekMoE: De motor achter de efficiëntie
DeepSeekMoE is het brein achter de indrukwekkende efficiëntie van DeepSeek. Het is het eigen MoE-model van DeepSeek. DeepSeekMoE bestaat uit meerdere experts en een gating mechanisme dat bepaalt welke experts per input worden geactiveerd (zie Figuur 2).
Traditionele MoE-modellen kampen met twee grote problemen:
- - Knowledge Hybridity – Experts leren overlappende concepten, waardoor hun specialisatie vervaagt.
- - Knowledge Redundancy – Meerdere experts slaan dezelfde informatie op, wat verspilling van resources veroorzaakt.
DeepSeekMoE lost deze belemmeringen op met twee kerninnovaties:
- - Fine-Grained Expert Segmentation – Door experts verder op te splitsen in kleinere, gespecialiseerde eenheden wordt redundantie verminderd en leert het model efficiënter. Daarnaast minimaliseert dit het leren van overbodige of dubbele informatie.
- - Shared Expert Isolation – Een subset van experts wordt constant actief gehouden om algemene kennis op te slaan, waardoor de rest van het model zich kan richten op gespecialiseerde taken.
Dankzij deze innovaties bereikt DeepSeekMoE een performance die vergelijkbaar is met dense modellen, maar met aanzienlijk minder rekenkracht. Zo presteert DeepSeekMoE 16B net zo goed als LLaMA2 7B, terwijl het 40% minder computationele resources verbruikt. Dit maakt het model niet alleen krachtig, maar ook schaalbaarder en efficiënter dan veel traditionele alternatieven.
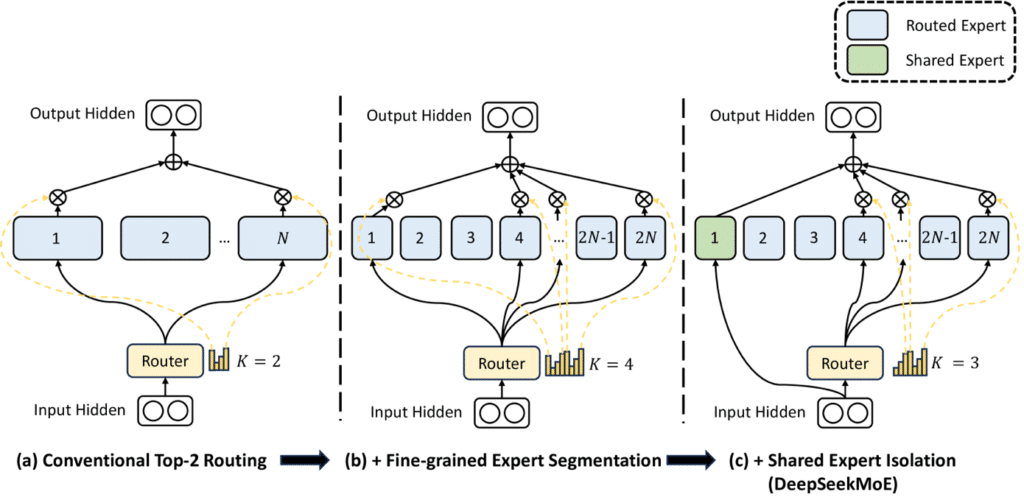
Figuur 2: Visualisatie van DeepSeekMoe (subfiguur c). Bij alle drie de architecturen zijn het aantal parameters en de computationele kosten overigens gelijk. (DeepSeekMoE)
Hoe worden experts slimmer?
DeepSeek gebruikt een geavanceerd trainingsproces met gradient-based optimalisatie. In tegenstelling tot conventionele neurale netwerken ontvangen bij DeepSeek alleen de geactiveerde experts updates, waardoor ze zich snel specialiseren in bepaalde taken. De experts leren dus alleen van input die voor hen relevant is.
Trainingsproces
- 1. Token routing
- De ‘gating functie’ bepaalt welke experts worden geactiveerd per token.
- 2. Forward pass
- Alleen de geselecteerde experts verwerken de token en genereren de output.
- 3. Backpropagation & learning
- De gradients van de experts en gating functie worden geüpdatet door de bijbehorende loss.
- Expert weights -> Iedere expert leert alleen van de tokens die hijzelf verwerkt.
- Gating functie -> leert om de toewijzing van experts te verbeteren.
De experts specialiseren zich door:
- - Gating function assignments – Vergelijkbare inputs worden naar eenzelfde expert subset geleid.
- - Reinforcement of patterns – Elke expert finetunet zijn responses op basis van frequente data types.
- - Regularization techniques – Voorkomt dat sommige experts overbelast raken en andere onderbenut blijven.
Doordat input met specifieke kenmerken of karakteristieken constant naar dezelfde expert wordt gestuurd, raakt deze expert gespecialiseerd in een bepaalde taak. Zo ontwikkelt de ene expert bijvoorbeeld een specialisatie in programmeercode, de ander in juridische teksten en een derde in alledaagse gesprekken.
Een veelvoorkomend risico tijdens dit proces is dat sommige experts overvraagd worden, terwijl andere ondervraagd blijven. Dit vermindert de efficiëntie en generalisatie van het model. Om dit te verhelpen gebruikt DeepSeek load balancing technieken, zoals auxiliary losses (DeepSeekMoE) waar het overvragen van een expert bestraft wordt, en bias-adjusted routing (DeepSeek-V3), waar elke expert een dynamische bias term krijgt op basis van de load.
Kortom, experts in de DeepSeek modellen verbeteren zichzelf door:
- - Het verwerken van vergelijkbare data in de loop van de tijd (natuurlijke specialisatie).
- - Het ontvangen van gerichte gradient updates (versterkt de expertise).
- - Het gebruik van load balancing technieken (efficiënte bijdrage van alle experts).
Uiteindelijk leiden de gespecialiseerde experts tot:
- - Verbeterde kwaliteit van de antwoorden.
- - Schaalbaarheid.
- - Real-time optimalisatie van resources wat het model versnelt en de kosten verlaagt.
DeepSeek-V2 en DeepSeek-V3
DeepSeek heeft zijn architectuur verder verfijnd in DeepSeek-V2 en DeepSeek-V3. Deze modellen introduceren nieuwe innovatieve functionaliteiten zoals:
- - Multi-Head Latent Attention (MLA)
Multi-Head Latent Attention, een nieuw sneller attentie-mechanisme dan de traditionele Multi-Head Attention (MHA). Conventionele Transformer-modellen gebruiken meestal Multi-Head Attention (MHA) (Vaswani et al., 2017), wat leidt tot een bottleneck die de inferentie vertraagt. Om dit te verhelpen, heeft DeepSeek voor de DeepSeek-V2 en DeepSeek-V3 modellen het MLA-mechanisme ontworpen (zie Figuur 3).
- - Auxiliary-Loss-Free Load Balancing
Een efficiënter alternatief op auxiliary loss functions. Veel MoE-modellen, en zo ook DeepSeekMoE, vereisen auxiliary loss functions om te voorkomen dat bepaalde experts overvraagd worden, terwijl andere ongebruikt blijven. DeepSeek-V3 lost dit op door de bias-adjusted routing strategy te introduceren, die de efficiëntie verbetert zonder in te leveren op load balancing.
- - FP8 Mixed Precision Training
DeepSeek gebruikt FP8 mixed precision arithmetic om geheugengebruik te verminderen en de rekentijd te verlagen. De berekeningen worden verdeeld tussen lagere en, waar nodig, hogere precisie, wat leidt tot een balans tussen efficiëntie en numerieke stabiliteit.
- - Multi-Token Prediction (MTP)
Met Multi-Token Prediction voorspelt het model meerdere toekomstige tokens tegelijk, wat zowel de training als inferentie versnelt. In traditionele LLM’s is dit één token per keer.
- - Geavanceerde Trainingsinfrastructuur
Een infrastructuur om GPU-bottlenecks te verhelpen en efficiënte training mogelijk te maken op extreem grote schaal. DeepSeek-V3 wordt getraind met een DualPipe pipeline parallelism. Door dit te combineren met een geoptimaliseerd cross-node communication system is DeepSeek-V3 een van de efficiëntste grootschalige MoE-modellen tot nu toe.
De verschillen tussen de drie varianten
In het kort zijn de verschillen tussen deze drie varianten van de modellen als volgt:
- - DeepSeekMoE is de basisversie die werkt met een traditionele MoE-architectuur en auxiliary loss functions voor load balancing.
- - DeepSeek-V2 introduceert verbeterde routing, FP8 mixed precision, en Multi-Token Prediction voor efficiëntere training en inferentie.
- - DeepSeek-V3 gaat nog een stap verder door de bias-adjusted routing, geavanceerdere mixed precision en verbeterde infrastructuur voor training op extreme schaal, wat de efficiëntie verder optimaliseert.
DeepSeek-V3 is dus het meest geavanceerde model en combineert de innovaties voor maximale prestaties en efficiëntie. (zie Figuur 4).

Figuur 3: Versimpelde visualisatie een aantal attenion mechanisms, met helemaal rechts Multi-head Latent Attention (MLA). Door de keys en values samen te comprimeren in een latent vector, maakt MLA het inferentieproces aanzienlijk sneller. (DeepSeek-V2)
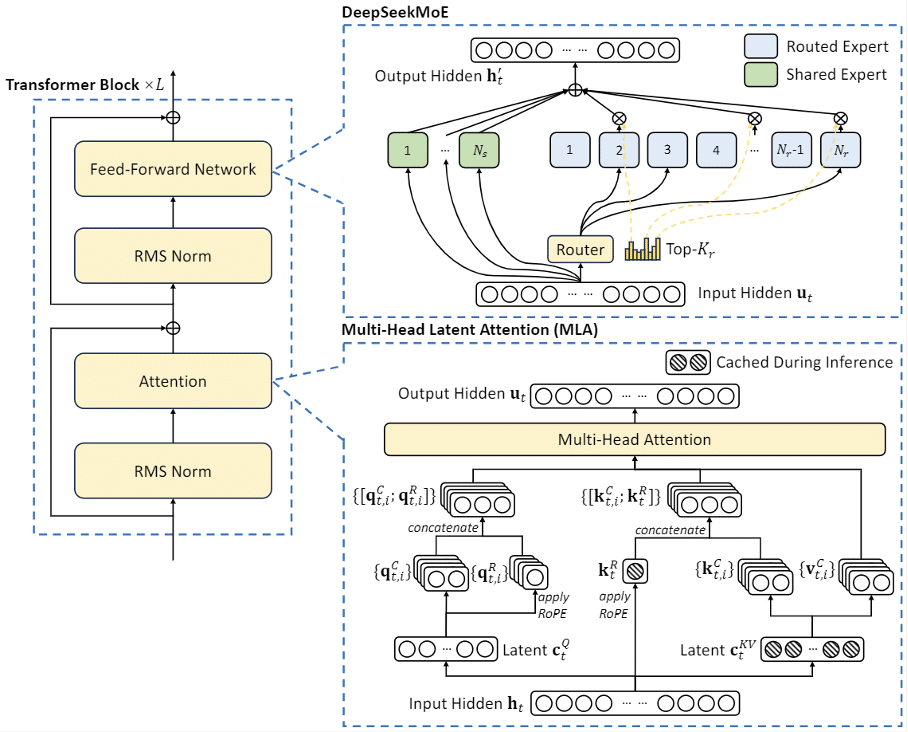
Figuur 4: De basisarchitectuur van DeepSeek-V2 en DeepSeek-V3. (DeepSeek-V2)
DeepSeek-R1: een technologische mijlpaal
DeepSeek-R1 is het model dat de echte doorbraak betekende. Een doorbraak die niet alleen de AI-community op zijn kop zette, maar ook een brede maatschappelijke impact heeft. Van kelderende beurskoersen tot verhitte politieke debatten over de toekomst van AI, DeepSeek-R1 bewees dat het niet zomaar een nieuw model is, maar een technologische mijlpaal.
Dit model maakt gebruik van Reinforcement Learning (RL), waardoor het kan redeneren en zelfstandig beslissingen nemen. Dit tilt niet alleen de prestaties naar een hoger niveau, maar laat ook zien wat er mogelijk is als je het model zélf laat nadenken.
Qua architectuur is DeepSeek R1 identiek aan de DeepSeek-V2 en DeepSeek-V3 variant. Het gebruikt de “only-pretrained” versie van deze modellen, maar heeft vervolgens een eigen post-training proces.
Simpel gezegd hebben de ontwikkelaars een test-verificatie harnas om het model heen gebouwd en een RL-proces hierop toegepast. Het model leert door beloond te worden voor goede uitkomsten. Tijdens dit proces hebben ze gebruik gemaakt van een simpele reward function (RL-equivalent van een loss-function). De functie is een gewogen som van twee componenten:
- - Accuracy Reward – Als de taak een objectief correct antwoord heeft (zoals een wiskundig probleem), dan wordt de juistheid geverifieerd door verschillende geschikte tests. Het model wordt beloond voor juistheid.
- - Format Reward – Het model wordt beloond voor het volgen van een gestructureerd redenatieproces.
Het gebruik van dit post-training proces leidt tot:
- - Self-verification – Het model dubbelcheckt zijn eigen antwoorden.
- - Extended chain-of-thought – Het model leert om zijn redenatie grondiger toe te lichten.
- - Exploratory reasoning – Het model onderzoekt meerdere benaderingen voordat het tot een conclusie komt.
- - Reflection – Het model bevraagt zijn eigen oplossingen en past zijn redenatieproces aan.
Dankzij dit proces is DeepSeek-R1 niet alleen accuraat, maar ook betrouwbaarder in het genereren van gestructureerde en gecontroleerde outputs.
Het uiteindelijke model
Hierdoor heeft het uiteindelijke model:
- - Een sterke chain-of-thought voor verifieerbare taken.
- - Afstemming op uiteenlopende user requests in het dagelijks gebruik.
- - Veiligere en meer gecontroleerde outputs.
Uitdagingen en risico’s
Hoewel DeepSeek veel potentie biedt, brengt het ook uitdagingen en risico’s met zich mee:
1. Beveiligingsrisico’s bij Open-Source
DeepSeek is open-source. Dat is zowel een kracht als een risico. Ondanks dat het hierdoor transparant is en het maatwerk mogelijk maakt, is tegelijkertijd het model ook kwetsbaarder voor misbruik voor kwaadaardige doeleinden, zoals het genereren van desinformatie, spam of onethische automatisering.
2. Ecosysteem en Ondersteuning voor Ontwikkelaars
In vergelijking met propriëtaire modellen (zoals OpenAI’s GPT-4) heeft DeepSeek een kleiner ecosysteem van integraties, tools en community-ondersteuning. Hierdoor kan het voor DeepSeek moeilijker zijn om op lange termijn met grotere modellen te concurreren. De adoptiegraad en het testen in de praktijk gaan bepalen of het model zich op de lange termijn effectief kan meten met de grotere concurrenten.
3. Bias en Taalbeperkingen
Het model is sterk geoptimaliseerd voor Engels en Chinees, wat de prestaties in andere talen kan beïnvloeden.
Er verschenen al snel meerdere artikelen waarin de inmenging en censuur van de Chinese overheid aangetoond werd (o.a. CNN, The Guardian). Ook zijn er de nodige privacybezwaren, waaronder datalekken, wat in meerdere landen heeft geleid tot opgelegde restricties op het gebruik van DeepSeek (voornamelijk in professionele setting) (o.a. Wiz, NowSecure, BBC).
Kortom, DeepSeek biedt veel potentie als open-source alternatief voor de closed-source LLMs die tot nu toe de markt leidden, maar het lange-termijn succes hangt af van continue verbeteringen in de nauwkeurigheid, veiligheid en de groei van het ecosysteem.
De toekomst van DeepSeek
DeepSeek bewijst dat open-source AI-modellen kunnen concurreren met propriëtaire modellen. Het biedt een nieuw perspectief op efficiënte, schaalbare AI en roept tegelijkertijd discussie op over transparantie, beveiliging en ethiek in AI-ontwikkeling.
Met DeepSeek-V3 laat het bedrijf zien dat open-source modellen niet alleen mee kunnen doen, maar mogelijk zelfs de toekomst van AI bepalen. De unieke combinatie van de goede prestaties, schaalbaarheid en efficiëntie maakt DeepSeek revolutionair. Of je nu een onderzoeker, ontwikkelaar of ondernemer bent – DeepSeek verandert de manier waarop we denken over Large Language Models. We kunnen zelfs stellen dat DeepSeek een nieuwe standaard heeft neergezet.
Bovendien maakt DeepSeek’s open-source en efficiënte karakter het behalve voor onderzoek, zeker ook aantrekkelijk voor business toepassingen. Daar in een latere blog meer over. Ben jij nu al benieuwd hoe jouw organisatie gebruik kan maken van deze ontwikkelingen? Wij helpen je graag verder! Maak een afspraak met ons en ontdek de mogelijkheden.


