

Voorbeelden van gender data bias in de praktijk
- Wanneer vrouwen betrokken zijn bij een auto-ongeluk, is de kans 47% groter op een ernstige verwonding dan bij een man, 71% groter op een middelmatige verwonding. Ook is de kans dat een vrouw omkomt bij een auto-ongeluk 17% groter dan bij de man[2]. Hoe dit komt? Vrouwen zitten gemiddeld meer naar voren, zijn minder lang, en moeten daardoor meer rechtop zitten om meer overzicht te hebben. Dat dit allemaal gebeurt, is te wijten aan het feit dat auto’s zijn ontworpen met gebruik van crash test dummies gebaseerd op de gemiddelde man. In 2011 zijn in de Verenigde Staten de eerste vrouwelijke crash test dummies meegenomen in de productie.
- Een algoritme om automatisch toptalenten te selecteren uit een groot aantal CV’s werd geïntroduceerd door Amazon in 2014. Veelbelovend, maar het bleek dat CV’s die het woord “women’s” bevatten lager werden beoordeeld. Ook identieke CV’s met als enige verschil man-vrouw werden verschillend beoordeeld. De oorzaak hiervan was dat het model getraind was op CV’s van 10 jaar terug in de technische sector. Vanwege de ondervertegenwoordiging van vrouwen in deze sector, bestond de trainingsdata vooral uit CV’s van mannen.
- In de medische wereld wordt ook gezien dat hartaanvallen minder snel herkend worden bij vrouwen dan bij mannen, en dat medicijnen vaker niet goed werken, simpelweg omdat ze getest zijn op een groep waarbij de meerderheid man is[6].
Bovengenoemde voorbeelden hebben eenzelfde oorzaak. De trainingsdata van de algoritmes is niet representatief voor de gehele bevolking en in deze gevallen geeft dat ernstige, en soms zelfs gevaarlijke, gevolgen.
Gender data bias in AI en Data Science
In machine learning modellen kan ook gender bias voorkomen. Maar ook in zelflerende algoritmes, waarvan verwacht zou worden dat ze neutraal zijn. Als er al een bias in de data zit, die in het algoritme wordt gestopt, kan dit niet alleen weerspiegeld worden in de output van het model. Het kan zelf worden vergroot. Een aantal technieken en methodes waar dit voorkomt binnen data science en/of AI worden hieronder uitgelicht.
Image Regognition[4]
Image recognition modellen geven de mogelijkheid om te leren uit afbeeldingen zonder specifieke kennis nodig te hebben.
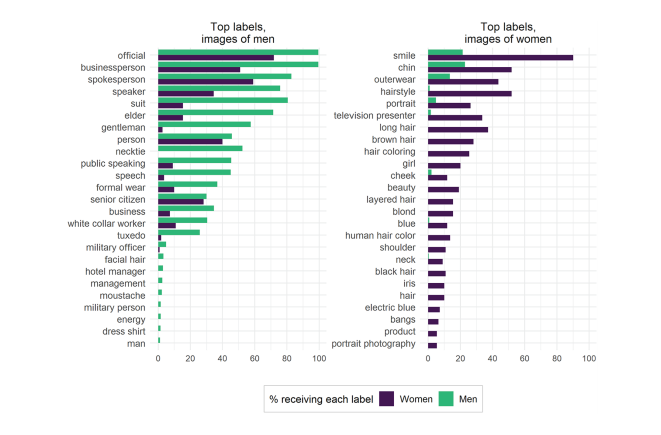
In image recognition software, die ook gebruikt worden door grote aanbieders, komen duidelijk stereotypen voor. Plaatjes van shoppen en wassen worden gelinkt aan vrouwen; coachen (van sport) en schieten aan mannen. Ook worden mannen die in keukens staan vaker gelabeld als vrouw door deze software. Daarnaast, wanneer er wordt gekeken naar welke labels worden gegeven aan afbeeldingen met mannen en afbeeldingen met vrouwen, worden daar, bijvoorbeeld door Google Cloud Vision, duidelijk verschillende labels gegeven.
Afbeeldingen van vrouwen worden veel vaker gelabeld op basis van uiterlijke kenmerken, terwijl afbeeldingen van mannen juist worden gelabeld op zakelijke kenmerken. Dit is ook te zien in de afbeelding. Daarnaast worden vrouwen überhaupt minder herkend op afbeeldingen dan mannen.
Voice Recognition
Voice AI, of speech recognition is een steeds meer gebruikte methode. Google heeft hiervoor een eigen, veel gebruikt model. Google zelf heeft gezegd dat hun speech recognition een nauwkeurigheid heeft van 95%. Het blijkt echter zo te zijn dat deze nauwkeurigheid niet voor elke groep hetzelfde is. Voor mannen blijkt de betreffende tool 13% accurater te zijn dan voor vrouwen. Ook voor verschillende dialecten en accenten werkt het beter dan voor andere[5].
Als per groep zou worden onderzocht hoe goed speech recognition werkt, kunnen ook gerichte verbeteringen doorgevoerd worden. Dit begint dus ook bij de data die erin wordt gestopt; als een gevarieerde groep hierbij wordt betrokken, is er een beter beeld van de nauwkeurigheid.
Natural Language Processing en Word Embeddings
In Natural Language Processing kan ook gender bias voorkomen. Dit komt bijvoorbeeld bij gebruik van word embeddings voor[7]. Word embeddings worden getraind op het samen voorkomen van woorden in tekst corpora. In een dergelijk model, getraind op Google News data, blijkt bijvoorbeeld dat de afstand tussen de woorden ‘nurse’ en ‘woman’, een stuk kleiner is dan de afstand tussen de woorden ‘nurse’ en ‘man’. Dit duidt op gender bias.
Er zijn voor machine-learning modellen zogenaamde ‘debias’ methodes, die de bias reduceren. Het woord ‘nurse’ zoals in het vorige voorbeeld, kan bijvoorbeeld meer naar het midden tussen ‘man’ en ‘woman’ worden verplaatst. Ook is het vaak mogelijk om de vergroting van de bias, die sommige machine-learning modellen veroorzaken, te verkleinen. Toch is in dit geval voorkomen beter dan genezen; de oorzaak zit immers al in de data die in het algoritme wordt gestopt. Daarnaast kunnen deze debias methodes pas worden toegepast wanneer de bias daadwerkelijk is opgemerkt door de ontwerper. Pas als je als data scientist bewust bent van de bias die in de data zit, kan je er wat tegen doen.
Gender bias is niet de enige bias die voorkomt in dergelijke algoritmes. Elk algoritme is sterk onderhevig aan de aannames die eraan ten grondslag liggen, en gender bias is daarom slechts een illustratie van het belang van de data die er in een algoritme gestopt wordt.
Conclusie
Gender data bias speelt dus een grote rol en heeft duidelijk gevolgen in de praktijk. Maar de eerste stappen zijn gezet. Om het probleem aan te pakken is allereerst erkenning van het probleem nodig. Het lijkt erop dat er meer bewustwording komt en dit onderwerp zichtbaarder wordt. Het is dus de ‘persoon’ achter het algoritme die van groot belang is voor de uitkomst van het algoritme. Dus, meer vrouwen in de data science is sowieso een goede start!
- A. Linder & M. Y. Svensson (2019) Road safety: the average male as a norm in vehicle occupant crash safety assessment, Interdisciplinary Science Reviews, 44:2, 140-153, DOI: 10.1080/03080188.2019.1603870
- https://www.theguardian.com/lifeandstyle/2019/feb/23/truth-world-built-for-men-car-crashes
- https://www.bbc.com/news/technology-45809919
- Schwemmer, C., Knight, C., Bello-Pardo, E. D., Oklobdzija, S., Schoonvelde, M., & Lockhart, J. W. (2020). Diagnosing gender bias in image recognition systems. Socius, 6, 2378023120967171
- Tatman, R. (2017). Gender and Dialect Bias in Youtube;s Automatic Captions
- Hamberg, K. (2008). Gender bias in medicine. Women’s health, 4(3), 237-243.
- Bolukbasi, T., Chang, K. W., Zou, J. Y., Saligrama, V., & Kalai, A. T. (2016). Man is to computer programmer as woman is to homemaker? debiasing word embeddings. Advances in neural information processing systems, 29, 4349-4357.


