

Wat is er nieuw en hoe pas je het toe in de praktijk?
Waarom MLflow?
Machine learning-projecten groeien in complexiteit. Vaak werken meerdere data scientisten en data engineers samen in één team aan de modellen. Het is natuurlijk belangrijk dat de modellen reproduceerbaar, schaalbaar en goed te beheren zijn tijdens het hele proces. Meerdere modellen, datasets, notebooks, scripts, zonder structuur raak je logischerwijs snel het overzicht kwijt. MLOps is onmisbaar geworden, het standaardiseert, automatiseert en maakt het werk schaalbaar. MLflow is hierbinnen de tool om grip op je ML-workflow te houden.
Met MLflow track je experimenten, registreer je modellen en krijg je automatisch inzicht in de prestatie (zoals statistieken als accuracy, precision en recal) direct in je interface. Geen extra code, wel meer controle.
Recent is versie 3.0 van MLflow uitgebracht met verschillende nieuwe features die inspelen op de nieuwste trends, zoals GenAI en LLM’s en op de behoefte aan grotere, snellere en reproduceerbare data science modellen.
Wat is er nieuw in MLflow 3.0?
MLflow 3.0 introduceert een aantal belangrijke vernieuwingen waarmee je sneller, overzichtelijker en breder inzetbaar kunt werken.
Introductie van de LoggedModel-architectuur.
De grootste ontwikkeling op het gebied van deep learning is de verbeterde modeltracking. Hoewel het in MLflow 2.0 technisch al mogelijk was om meerdere modelcheckpoints te loggen, was dit niet gestandaardiseerd en ontbrak vaak de directe kopppeling tussen een gelogd model en de context waarin het was getraind en geëvalueerd. De vernieuwde modeltracking biedt uitgebreide herleidbaarheid tussen verschillende modellen, runs en evaluatiemetrics via de LoggedModel architectuur. Met deze architectuur kunnen verschillende model checkpoints en metadata binnen een enkele run worden gelogd en kan de prestatie daarvan gevolgd worden op verschillende datasets. Dit is vooral handig in deep learning-workflows, waar je modellen op verschillende trainingsmomenten wilt opslaan en vergelijken. Je kunt binnen een training meerdere checkpoints loggen en deze direct terugvinden met prestatiegegevens op verschillende datasets. Door gebruik te maken van de step-parameter in de logfuncties kun je checkpoints loggen op specifieke trainingsmomenten. Elk gelogd model krijgt een unieke model-ID waarmee het later eenvoudig gerefereerd kan worden. Uiteindelijk kun je op basis van prestatiemetrics het best presterende model selecteren uit de verschillende checkpoints.
Kortom: je hoeft niet langer handmatig structuur aan te brengen. MLflow doet het voor je. Elke gelogde modelvariant krijgt een unieke ID, gekoppeld aan zijn context, training step en evaluatieresultaten. Je kan eenvoudig terugvinden welk model op welk moment is gelogd en hoe het model heeft gepresteerd.
Ondersteuning voor LLM’s en GenAI
MLflow biedt nu:
- Prompt logging en output tracking;
- Je kunt prompts en gegenereerde outputs loggen, wat het eenvoudiger maakt om experimenten met LLMs reproduceerbaar te maken en te vergelijken.
- Evaluatie via de GenAI Evaluation Suite;
- Met de GenAI evaluation suite kan je GenAI applicaties onderhouden, zoals je dit bij traditionele machine learning modellen ook doet. Niet alleen om de kwaliteit van de toepassingen te meten, maar te verbeteren en behouden gedurende de cyclus.
- Een prompt registry.
Voor herbruikenbare en betere prompts biedt MLflow 3.0 een prompt registry. Je kan je prompts automatisch verbeteren aan de hand van de evaluatiefeedback en gelabelde datasets. Binnenkort verschijnt er een aparte blog over hoe je LLM-evaluatie effectief inzet met MLflow 3.0.
Use Case: Image classificatie met MobileNetV2
Data en Preprocessing
We gebruiken de Intel Image Classification
Met landschapsfoto’s van Kaggle, gecategoriseerd in verschillende klassen. Na het opsplitten in train-, validatie- en testsets voeren we data-augumentatie uit met Keras.
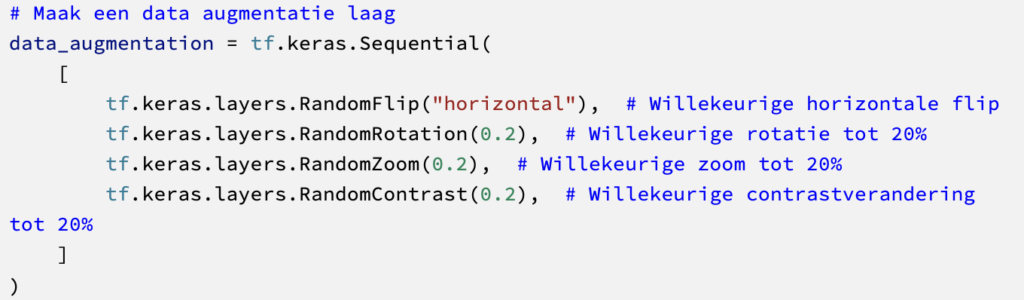
Hieronder voorbeelden van hoe de afbeeldingen eruitzien na het uitvoeren van de augmentatie.

Daarna volgt de pre-processing met dezelfde pipeline als MobileNetV2.
Model MobileNetV2 en MLflow integratie
We kiezen voor MobileNetV2 vanwege balans in performance en snelheid. Het model is lightweight, pre-trained en we bevriezen de basislagen omdat we niet alle weights opnieuw willen trainen.

In plaats van autolog gebruiken we bewuste, handmatige logging. Dat geeft meer grip op wat wel en niet gelogd wordt, en zo houdt je betere controle over je model en wat je erover opslaat. Dit is essentieel voor schaalbare evaluatie. We loggen checkpoints per epoch, verschillende metrics per datasets en parameters per modelvariant. Dit gebeurt met een custom MLflow callback, die alles na elke epoch automatisch logt.

Deze functie wordt gebruikt in een custom callback class die tijdens het trainen na elke epoch de informatie logt voor het model en de bijbehorende trainingsrun.

Model trainen en run management
Nu het model gecompileerd is, zijn we klaar om het model te trainen. Omdat we ook gebruik willen maken van MLflow om het trainen te tracken en zo de performance van het model inzichtelijk te maken, moet er eerst een tracking experiment worden geïnitieerd. Hierbij geef je aan waar alle training runs te vinden zijn en kan je de run een experimentnaam meegeven.

Het model is klaar om te trainen en wordt per run met MLflow gedraaid. Hierdoor kan binnen een experiment verschillende runs gedraaid worden. Deze kunnen later met elkaar worden vergeleken. Een run zoals wij hem hebben gedraaid ziet er als volgt uit:


Na het draaien van het model kunnen we de nieuwe functionaliteit van MLflow 3.0 gebruiken om de gelogde modellen en de bijbehorende resultaten terug te vinden via onderstaande code:

Met MLflow 3.0 kun je eenvoudig filteren op prestaties om het beste model te selecteren. Een fijne toevoeging is de mogelijkheid tot filtering. Je kunt voorwaarden meegeven bij het zoeken naar het beste en meest passende model. Denk hierbij aan zoektermen zoals “accuracy > 0.9”. Op basis daarvan kun je telkens het best presenterende model selecteren om op te slaan en te deployen.
MLflow UI
Voor deze case hebben we gekeken welk model het beste presteert op basis van de epoch. Wanneer we naar de Run-pagina gaan van de MLflow UI, kunnen we de run en de gelogde modellen met de juiste benamingen zien.
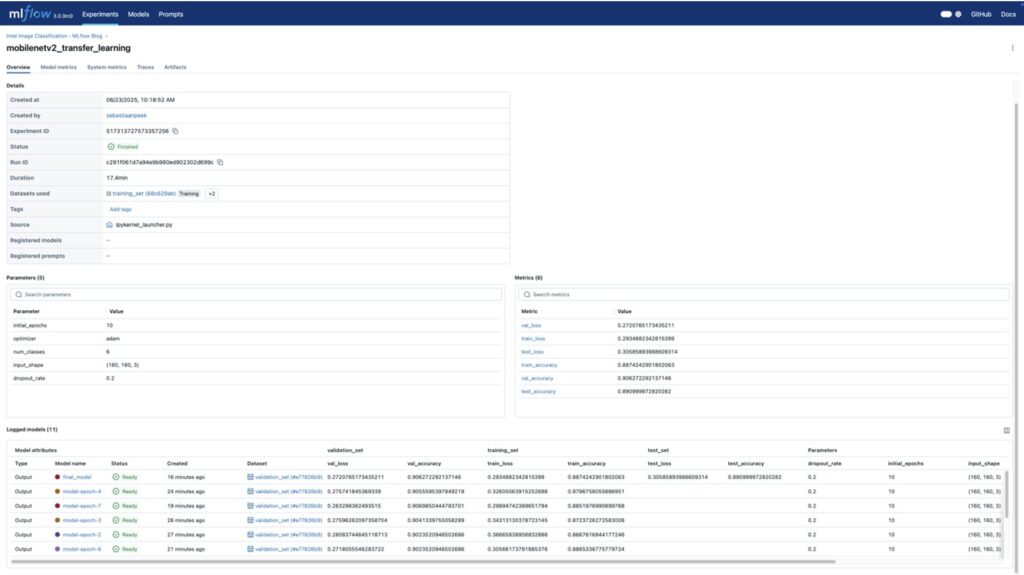
De Models-tab toont alle opgeslagen modellen met de bijbehorende metrics.

De artifacts-tab zijn alle extra bestanden, resultaten en figuren die per model opgeslagen kunnen worden. Zoals informatie over de omgeving waarin het model is gedraaid, of de opzet van het model.

Daarnaast biedt MLflow ook de vrijheid om handmatig bestanden/figuren toe te voegen binnen de run. Deze zijn terug te vinden in de Artifacts-tab van de Run, en kunnen nuttig zijn voor het loggen van eventuele extra informatie, zoals bijvoorbeeld een confusion matrix.

Next steps
Met deze use case laten we zien hoe je met MLflow 3.0 een basis kunt leggen voor een gestructureerde en reproduceerbare machine learning-workflow. Maar natuurlijk is er binnen MLOps nog veel meer mogelijk om je platform verder te verbeteren.
Wil je MLflow verder integreren in je organisatie? Overweeg dan:
- CI/CD-integratie voor automatische retraining & deployment;
- Stage transitions te gebruiken binnen model registry ("Staging", "Production") om je model lifecycle beter te beheren;
- Alerts instellen voor modeldrift via monitoringtools.
Wat je nodig hebt, hangt af van waar je staat in je MLOps proces. Hierbij is de volwassenheid van je data science proces, de schaal waarop je werkt en de complexiteit van je modellen van belang.
Key takeaways
- LLMs & GenAI: Meerdere nieuwe functionaliteiten gericht op LLMs, inclusief prompt logging en evaluatie via de GenAI evaluation suite.
- Bewuste evaluatie: Expliciete logging in plaats van autolog zorgt voor bewustere evaluatie van modellen.
- Dankzij de uitgebreide LoggedModel-architectuur staat het model centraal binnen de gehele MLflow lifecycle. Dit biedt niet alleen controle over experimenten, maar ook over het beheren, versioneren en uitrollen van modellen richting productie, waardoor je de volledige development workflow flexibel en schaalbaar kunt inrichten.
- UI: Een centrale omgeving waar alle resultaten rondom modellen en runs overzichtelijk worden weergegeven in een UI, waardoor het vergelijken van modellen snel en eenvoudig wordt.
- Selectie: Filter eenvoudig het best presterende model per use case.
Ook aan de slag met MLOps en deep learning in jouw organisatie?
Bij DSL denken we graag met je mee. Plan een kennismakingsgesprek.


