

Als je naar series zoals CSI kijkt herken je scènes zoals deze vast wel: rechercheurs zijn de dader op het spoor en kijken verwachtingsvol naar beelden van beveiligingscamera’s. Op het eerste gezicht lijken de beelden niet de gewenste informatie te tonen, maar dan valt hun oog op een nauwelijks zichtbaar detail. Ze zoomen in, verbeteren de beeldkwaliteit en… het detail wat dan zichtbaar wordt, onthult belangrijke informatie en zorgt voor een doorbraak in het onderzoek.

- Medical imaging (bron): door beperkingen zoals weinig tijd of bewegingen van de patiënt is de resolutie van MRI-scans niet altijd zo hoog als gewenst. Superresolutie wordt daarom ingezet om de kwaliteit van MRI-scans te verbeteren, wat dokters kan helpen bij het stellen van een diagnose.
- Satellite imaging (bron): satellietbeelden worden van een grote afstand genomen en zijn daarom beperkt in het tonen van details. Objecten zoals auto’s zijn soms bijvoorbeeld slechts 10 pixels groot. Superresolutie kan helpen om objecten beter te kunnen detecteren.
- Beveiliging (bron): omdat er niet overal HR-camera’s geplaatst kunnen worden, geven beveiligingscamera’s vaak lage resolutie beelden. Het verbeteren van de kwaliteit van camerabeelden kan helpen om details – denk bijvoorbeeld aan kentekens – beter zichtbaar te krijgen.
Klassieke methoden om extra pixels toe te voegen aan een afbeelding genereren nieuwe pixels op basis van omliggende pixels. Helaas blijkt superresolutie niet zo simpel; deze zogenoemde interpolatietechnieken resulteren vaak in wazige of gepixelde afbeeldingen. Met de ontwikkelingen in deep learning methoden heeft de ontwikkeling van superresolutie een vogelvlucht genomen in de afgelopen jaren. Op basis van een grote dataset van afbeeldingen kunnen neurale netwerken leren details toe te voegen aan afbeeldingen. Hoe gaat dat in zijn werk? In deze blog geven we een introductie in supervised deep learning methoden voor superresolutie.
Data preparatie
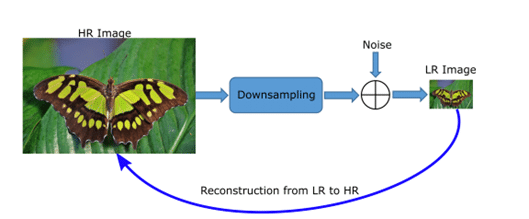
De eerste stap bij supervised learning is het genereren van een dataset om een model mee te kunnen trainen. Het doel van superresolutie modellen is om een mapping te leren tussen lage resolutie (LR) en hoge resolutie (HR) afbeeldingen: oftewel, hoe maak je van een LR afbeelding een HR afbeelding. Dit kan door een LR afbeelding als input te geven aan het model en een HR-afbeelding als ground truth; zo kan het model een functie leren om op basis van een LR afbeelding zo dicht mogelijk bij de werkelijke afbeelding te komen. We hebben dus LR-HR paren nodig voor het trainen van een model. Zo’n dataset van LR-HR paren wordt vaak gecreëerd door een set HR afbeeldingen te nemen en hierop een functie toe te passen om de kwaliteit van de afbeeldingen te verlagen. Dit kan worden gedaan door pixels te verwijderen, vervaging toe te passen en ruis toe te voegen. Op deze manier wordt er van elke afbeelding een versie in goede en slechte kwaliteit gegenereerd, die we kunnen voeren aan het model.
Model frameworks
Nu we weten wat voor dataset we nodig hebben, kunnen we gaan kijken naar de verschillende type modellen die we kunnen gebruiken voor superresolutie. Superresolutie is een zogenaamd ill-posed problem: een LR afbeelding kan met meerdere HR afbeeldingen overeenkomen, er bestaat niet één juiste oplossing. Daarom is de manier van het toevoegen van pixels, upsampling genoemd, een belangrijke component in de methode. Er bestaan grofweg vier model frameworks met verschillende benaderingen ten opzichte van upsampling:
- Pre-upsampling: in deze methode wordt de LR afbeelding eerst vergroot (met klassieke interpolatietechnieken) om een ruwe HR afbeelding te genereren. Vervolgens worden Convolutional Neural Networks (CNN's) gebruikt om een mapping te leren tussen deze ruwe HR afbeelding en de originele HR afbeelding. Het voordeel van deze methode is dat het neurale netwerk alleen deze ene mapping hoeft te leren, omdat het vergroten van de afbeelding gebeurt met klassieke interpolatiemethoden. Het nadeel van deze methode is dat dit blurring kan veroorzaken.
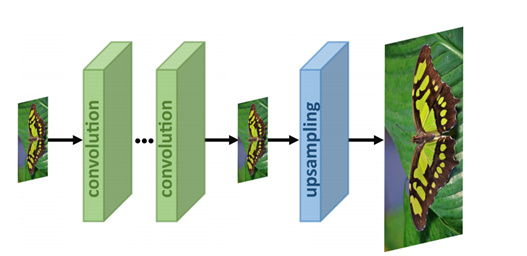
- Post-upsampling: hier gaan de LR afbeeldingen eerst door de convolutional layers, en wordt upsampling pas in de laatste laag uitgevoerd. Het voordeel van deze benadering is dat de mapping functie in een lagere dimensie wordt geleerd, waardoor de rekenprocessen minder complex zijn.
- Iterative up-and-down sampling: hier wordt het proces van up- en downsampling afgewisseld. De modellen die gebruikmaken van dit framework zijn vaak beter in het vinden van diepe relaties tussen de LR-HR paren en resulteren daarom vaak in kwalitatief betere afbeeldingen.
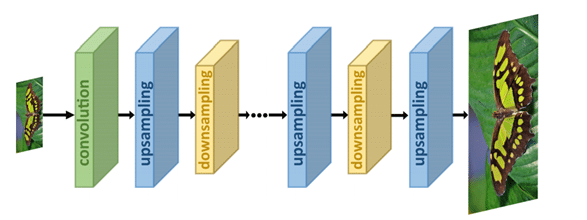
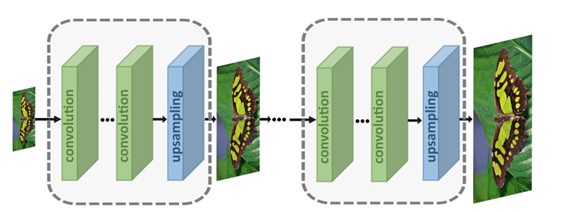
- Progressive-upsampling: in dit framework worden meerdere CNN’s gebruikt om in kleine stappen een steeds grotere afbeelding te genereren. Door de moeilijke taak in een aantal simpelere taken op te splitsen wordt de moeilijkheidsgraad wat lager, wat de resultaten kan verbeteren.
Leerstrategieën
Voor het trainen van een superresolutie model is het noodzakelijk om het verschil tussen de gegenereerde HR afbeelding en de originele HR afbeelding te kunnen meten. Dit verschil wordt gebruikt om de foutmarge in de reconstructie van de HR afbeelding te berekenen en zo het model te optimaliseren. Voor deze berekening worden loss functies gebruikt. Een aantal voorbeelden van zulke loss functies zijn:
- Pixel loss: pixel loss is de meest simpele loss functie, waar elke pixel in de gegenereerde afbeelding direct wordt vergeleken met elke pixel in de originele afbeelding. Omdat uit onderzoek is gebleken dat dit niet geheel de kwaliteit van de reconstructie representeert, worden er ook andere functies gebruikt.
- Content loss: deze functie verzekert visuele gelijkenis tussen de originele afbeelding en de gegenereerde afbeelding door de content te vergelijken in plaats van de individuele pixels. Het gebruik van deze loss functie zorgt dus voor betere perceptuele kwaliteit en meer realistische afbeeldingen.
- Adversarial loss: wordt gebruikt in GAN-gerelateerde architecturen. Generative Adversarial Networks (GANs) bestaan uit twee neurale netwerken – de generator en de discriminator – die met elkaar in duel gaan (meer weten over GANs? Lees het in deze blog). In het geval van superresolutie probeert de generator afbeeldingen te genereren waarvan de discriminator denkt dat deze echt zijn. De discriminator probeert de originele HR afbeeldingen van de gegenereerde afbeeldingen te onderscheiden. Dit trainingsproces resulteert uiteindelijk in een generator die goed is in het genereren van afbeeldingen die vergelijkbaar zijn met de originele afbeeldingen.
- Total variation loss: total variation loss berekent het absolute verschil tussen omliggende pixels en meet de hoeveelheid ruis in een afbeelding. Deze functie wordt gebruikt om de hoeveelheid ruis in de gegenereerde afbeeldingen te verminderen.
Evaluatie
Voor de evaluatie van de resultaten van getrainde superresolutie modellen wordt de kwaliteit van gegenereerde afbeeldingen gemeten, hier bestaan verschillende methoden voor. Hierbij kan onderscheid gemaakt worden tussen objectieve en subjectieve methoden. Omdat subjectieve methoden vaak veel geld en tijd kosten, vooral als de dataset groot is, worden objectieve methoden vaker gebruikt bij superresolutie.
- Peak signal-to-noise ratio (PSNR): deze kwantitatieve metriek is gebaseerd op de individuele pixels en geeft de verhouding tussen signaal en ruis.
- Structural similarity index metric (SSIM): valt ook onder de objectieve methoden en meet de structurele gelijkenissen tussen afbeeldingen door contrast, lichtintensiteit en structurele details te vergelijken tussen afbeeldingen.
- Opinion scoring: een subjectieve methode, waarbij mensen worden gevraagd om specifieke criteria zoals scherpte, kleur of natuurlijke uitstraling te beoordelen.
Discussie
Nu we een aantal methoden hebben besproken hoe je met behulp van deep learning superresolutie modellen kan trainen, kan het zijn dat je denkt: wauw, met superresolutie kunnen we zo allerlei details tevoorschijn toveren die we anders niet konden zien! In de praktijk ligt het net wat ingewikkelder. Een tijdje terug circuleerde onderstaande foto op sociale media:

Referenties
- Reeth et al. 2012: https://onlinelibrary.wiley.com/doi/epdf/10.1002/cmr.a.21249
- Bashir et al. 2021: https://arxiv.org/abs/2102.09351
- Yue et al. 2016: https://www.researchgate.net/publication/303182546_Image_super-resolution_The_techniques_applications_and_future
- Shermeyer et al. 2019: https://arxiv.org/abs/1812.04098
- Gohshi 2015: https://www.scitepress.org/Papers/2015/55598/55598.pdf


