
Geautomatiseerd verzamelen van data
Data is de fundering voor een geslaagd data science project. Soms is alleen niet alle gewenste data direct voor handen. Een model kan dan nog zo innovatief zijn, bij het ontbreken van de juiste features staat je project snel op losse schroeven.
Externe data. Een term die wij vaak voorbij horen komen. Data van andere partijen, dat moeten wij hebben! Zonder al te sarcastisch te worden, regelmatig wordt dit geroepen zonder dat er een concreet idee is wat de toegevoegde waarde is van externe data. Is dit idee wel aanwezig? Top! Wat zijn dan de mogelijkheden?
Regelmatig bieden externe bronnen, zoals overheidsinstanties of sociale media platformen, een API aan. Dit maakt zaken een stuk makkelijker. Via deze weg wordt (soms tegen betaling) data op verzoek aangeboden. Mocht dit niet het geval zijn dan is webscraping mogelijk een goed alternatief.
Let op! Het is nog altijd discutabel of webscraping legaal is. Check voordat je een website gaat scrapen dus of wat je gaat doen legaal en moraal verantwoord is. Zolang een website publiek toegankelijk is, is er veel toegestaan. Echter websites scrapen en daarmee een volledige database kopiëren mag bijvoorbeeld niet. Check dit dus altijd goed voordat je begint! Deze blog is enkel educatief.
WAT IS WEBSCRAPING?
Als je een website wilt gaan scrapen om data te verzamelen is er niet één generieke oplossing. Elke website zit namelijk anders in elkaar. Sommige websites hebben een RSS-feed, een web feed waarop updates van een website worden aangeboden in standaard XML-format. Via deze RSS-feeds is data gemakkelijk binnen te halen. Echter bestaat er ook een ander uiterste, sommige websites zijn beschermd tegen webscraping. Zo worden bepaalde IP-adressen geblokkeerd wanneer deze te veel verzoeken sturen. VPN kan een oplossing zijn, al worden deze soms ook herkent op basis van IP.
Wat nu? Rotating proxies kunnen een oplossing bieden. Echter zijn sommige websites op geavanceerdere wijze beschermt tegen webscraping. Een verzoek aan een website bevat ‘headers’, hierin staat onder meer informatie over diegene die het verzoek doet. Geautomatiseerd scrapen kan onder andere dus herkend worden a.d.h.v. deze headers. In dit kat en muis spel zijn hier ook weer oplossing voor te vinden. Al gaat het beschermen van websites inmiddels zo ver dat hier machine learning modellen voor getraind zijn! Soms is daarom de conclusie simpelweg dat een website niet de scrapen is.
In deze blog zal ik ingaan op een situatie waarin een website publiek toegankelijk is, dus zonder login functionaliteiten. Tevens waar webscraping geaccepteerd wordt zolang het aantal verzoeken binnen de perken blijft. Wanneer je 100 verzoeken per minuut stuurt, kan een website je tijdelijk blokkeren als preventie tegen DDoS aanvallen. Een webpagina kunnen scrapen is stap 1, maar we willen dit vervolgens ook echt geautomatiseerd doen. In deze blog zal ik daarom tot slot ook ingaan op het ‘schedulen’ van een webscraper in de Azure Cloud.
WEBSCRAPING IN PYTHON
In deze blog maak ik gebruik van webscraping in Python 3.7. Verder zal ik gebruikmaken van de volgende Python packages
Om informatie van een specifieke URL te halen, gebruiken we allereerst requests om vervolgens de opgevraagde HTML te verwerken met BeautifulSoup.
import pandas as pd
import requests
from bs4 import BeautifulSoup
page = requests.get(URL, headers={‘User-agent’: ‘Data Science Lab.’})
soup = BeautifulSoup(page.text, “html.parser”)
Hier is ’URL’ de desbetreffende URL van de webpagina welke je wilt gaan scrapen. In het resulterende object soup kunnen we hierna alle inhoud van de webpagina vinden. Om vervolgens tot bepaalde specifieke informatie te komen dienen we in de HTML van de webpagina te duiken. Willen we bijvoorbeeld een review-veld ophalen, in welk HTML-element staat dit dan?Hieronder zien we een voorbeeld van een webpagina met reviews. In Google Chrome kunnen we via ‘rechtermuisknop’ > ‘Inspect’ de HTML-elementen inzien en zoeken bij bepaalde stukken tekst. In dit voorbeeld zien we dat de review tekst staat in een veld met div header waar class=”review-content_text”,
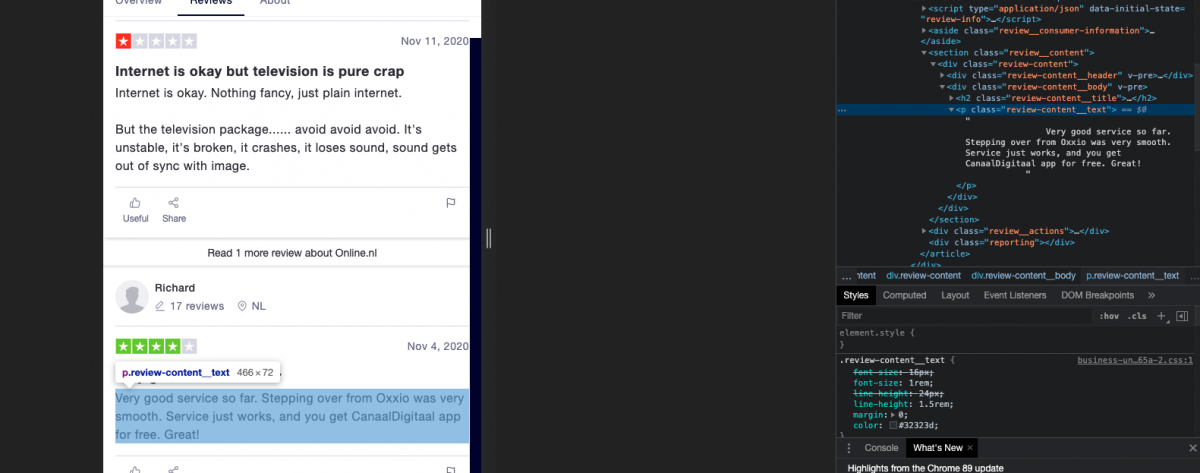
Stel dit veld staat in een div header waarbij we dit veld kunnen specificeren met class=”review-content_text”, dan kunnen we deze data op de volgende manier uit soup halen.
review = soup.findAll(“div”, {“class”: “review-content_text”})
Hiermee halen we alle div headers op als lijst waarin de class de naam ‘review’ heeft op de webpagina. Op eenzelfde manier kunnen alle div headers worden opgehaald zonder een specifieke class naam mee te geven. Hetzelfde geld natuurlijk voor alle andere headers zoals p, h2, etc. Hierbij kunnen we dan ook weer filteren op tags als href, id, etc. Een andere optie is de find functie waarmee enkel het 1e gevonden header object terug wordt gegeven.
Zoeken op meer gelaagd niveau werkt vervolgens op precies dezelfde manier. Wanneer een div header vervolgens ook weer een div element bevat, kunnen we deze ook gericht ophalen. Hieronder op twee manieren weergegeven.
# Gebruik makende van .findAll
review = soup.findAll(“div”)[1].find(“div”)
# Gebruik makende van .find
review = soup.find(“div”).find(“div”)
Op deze manier kan allerlei specifieke data van een webpagina worden gehaald. Op dezelfde wijze kunnen wij ook een review ID verkrijgen en eventuele extra review informatie. Na het opschonen van deze data is het klaar om gebruikt te worden! We slaan de velden op in een Pandas DataFrame en pushen dit naar onze database.
# Pandas dataframe maken
import pandas as pd
review_df = pd.DataFrame({‘ReviewID’: review_IDs, ‘Review’: review})
# Verzamelde data opslaan in de database
review_df.to_sql(‘ReviewTable’, con=SQLAlchemy_conn, schema=‘dbo’, if_exists=‘replace’)
Voor we een webscraping script gaan gebruiken is het belangrijk om te beseffen dat webpagina’s kunnen veranderen. Dit betekent dat je script stuk kan lopen. Het is daarom verstandig om enige ‘error handling’ in te bouwen. Zorg dat er de benodigde ‘try & except’ statements om je code heen staan. Als er iets misgaat, log het dan en zorg dat je op de hoogte wordt gesteld van errors in het scrape proces. Bijvoorbeeld door e-mail notificaties.
Nu we data kunnen ophalen is het veelal ook gewenst om dit structureel te doen en bijvoorbeeld weg te schrijven naar een database. Dit kan natuurlijk op verschillende manieren gedaan worden. Ik geef als slot van deze blog een oplossing hiervoor in de Azure Cloud.
EEN WEBSCRAPER DEPLOYEN
Nu we in de basis weten hoe we een webpagina kunnen scrapen, is de volgende stap om dit structureel en gepland te gaan doen. Het kan bijvoorbeeld zo zijn dat we ieder uur, dag, week of maand informatie van een website willen halen. Je kan dan telkens handmatig je script gaan runnen, maar dit is natuurlijk niet heel wenselijk.
Het is onder andere mogelijk om dit op een lokale server te doen, bijvoorbeeld met Windows Scheduler. Een andere optie is om dit in de Cloud te laten draaien, bijvoorbeeld in AWS of Azure Cloud. Die laatste optie ga ik verder op in.
Om een Python script in de Microsoft Azure Cloud te schedulen, gebruik ik het volgende:
- Docker
- Gunicorn
- Azure DevOps
- Azure Cloud resources
- App plan
- Function app
- Container registry
Duidelijk hieruit is dus dat ik een Docker container maak en hierbij gebruik maak van Azure functions. Hierbij bouw ik de Docker container via een Pipeline in Azure DevOps.
Allereerst de structuur van de map van waaruit we de container bouwen. Deze ziet er als volgt uit:
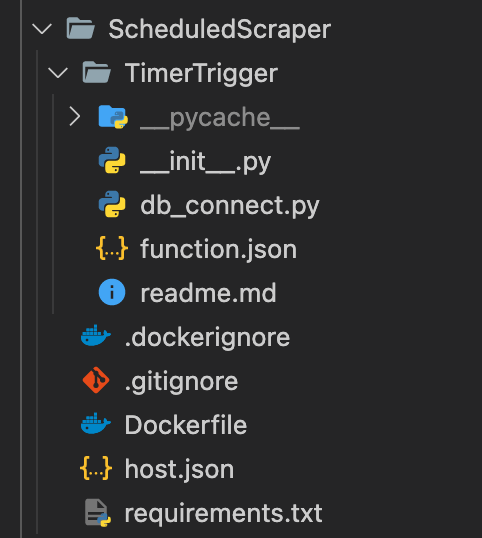
Een korte uitleg bij een aantal deze bestanden:
- py bevat de code voor de webscraper.
- Dockerfile, hier komen we dadelijk op terug.
- txt, bevat de packages welke benodigd zijn om te scrapen. Dit zijn dus i.i.g. requests, BeautifulSoup, pandas & azure-functions.
- py bevat enkele functies voor database communicatie, het wegschrijven naar de database laat ik in deze blog verder buiten beschouwing.
- json is een file waarin we de versie bijhouden en de ‘timeout’ limiet staat ingesteld als “functionTimeout”. Dit laatste is afhankelijk van hoelang het script runt.
- json, hierin staat welke file op schema gerund moet worden en volgens welk CRON schema. Dit ziet er in ons geval als volgt uit, waarbij we dagelijks scrapen om 01:00 uur.
{
“scriptFile”: “__init__.py”,
“bindings”: [
{
“name”: “mytimer”,
“type”: “timerTrigger”,
“direction”: “in”,
“schedule”:“0 0 1 * * *”
}
]
}
Om een container te maken is een Dockerfile vereist. Belangrijk hierin is om de Dockerfile zo te schrijven dat alle vereisten aanwezig zijn in de container welke wordt gebouwd. Via verschillende commands worden deze, zoals de packages in de requierements.txt, geïnstalleerd en kopiëren we de benodigde files naar de container. Dit resulteert in de onderstaande Dockerfile. Dit kan overweldigend overkomen, maar maak je geen zorgen. De meeste tijd gaat uit naar het installeren van de SQL Driver in de Docker Container.
FROM mcr.microsoft.com/azure-functions/python:3.0
ENV AzureWebJobsScriptRoot=/home/site/wwwroot \
AzureFunctionsJobHost__Logging__Console__IsEnabled=true
COPY . /home/site/wwwroot
COPY requirements.txt /home/site/wwwroot
RUN apt-get update && \
apt-get -y install sudo
RUN sudo apt-get -y install poppler-utils
RUN apt-get -y install curl
RUN apt-get -y install –reinstall build-essential
RUN sudo curl https://packages.microsoft.com/keys/microsoft.asc | apt-key add –
RUN sudo curl https://packages.microsoft.com/config/debian/9/prod.list > /etc/apt/sources.list.d/mssql-release.list
RUN sudo ACCEPT_EULA=Y apt-get install msodbcsql17
RUN sudo ACCEPT_EULA=Y apt-get install mssql-tools
RUN echo ‘export PATH=”$PATH:/opt/mssql-tools/bin”‘ >> ~/.bash_profile
RUN echo ‘export PATH=”$PATH:/opt/mssql-tools/bin”‘ >> ~/.bashrc
RUN /bin/bash -c “source ~/.bashrc”
RUN sudo apt-get install -y unixodbc-dev
RUN cd /home/site/wwwroot && pip install -r requirements.txt
Hiermee kunnen wij een Docker container bouwen welke gebruikt kan worden in de Azure Function App als ‘scheduled webscraper’. Echter als we nu een aanpassing maken in de webscraper moeten we telkens handmatig de container bouwen en pushen. Dit kan eenvoudiger. Namelijk via een Pipeline in Azure DevOps.
In DevOps is het mogelijk om een Pipeline te maken waarmee Artifacts worden gebouwd. Deze kunnen vervolgens in een Release pipeline handmatig in productie worden gezet. Echter voor deze blog houd ik het bij een Pipeline welke bij een wijziging op de master branch getriggerd wordt en een Docker container bouwt en direct pusht. Voor situaties waar een webscraper in productie wordt gebruikt, is een release stap met de benodigde checks wel wenselijk.
In Azure DevOps bestaat de Pipeline dus simpelweg uit 2 taken. Het bouwen en het pushen van de Docker container. Hiervoor is wel een service connection nodig, zodat bekend is naar welke container registry in Azure de Docker Container gepusht dient te worden. Als we de Pipeline linken aan de master branch van de desbetreffende repository en hier een trigger instellen zodat bij elke wijziging de Pipeline getriggerd wordt, dan hebben we een continu ‘CICD’ proces ingeregeld.
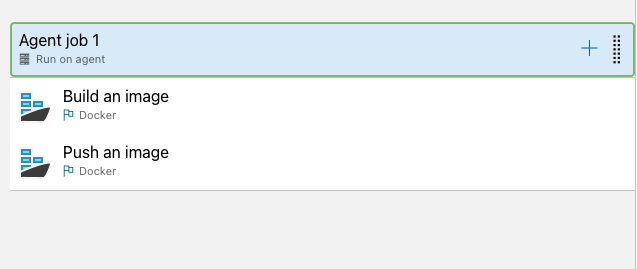
Als gezegd bestaat de Pipeline uit 2 stappen. Een Docker build taak en een Docker Push taak (zoals hierboven te zien). In de Docker build taak verwijzen we naar onze Dockerfile, de service connection, de container registry in Azure en geven we een image naam mee. Dit is standaard de naam van de repository + het build ID.
In de desbetreffende Azure Function dienen we nu alleen nog te verwijzen naar de Docker container welke gebouwd wordt middels de Pipeline. Dit kan in Azure onder ‘Settings>Container settings’. Hierin verwijzen we naar de Azure Container Registry en de Docker Container welke hierin staat. Hieronder een voorbeeld.
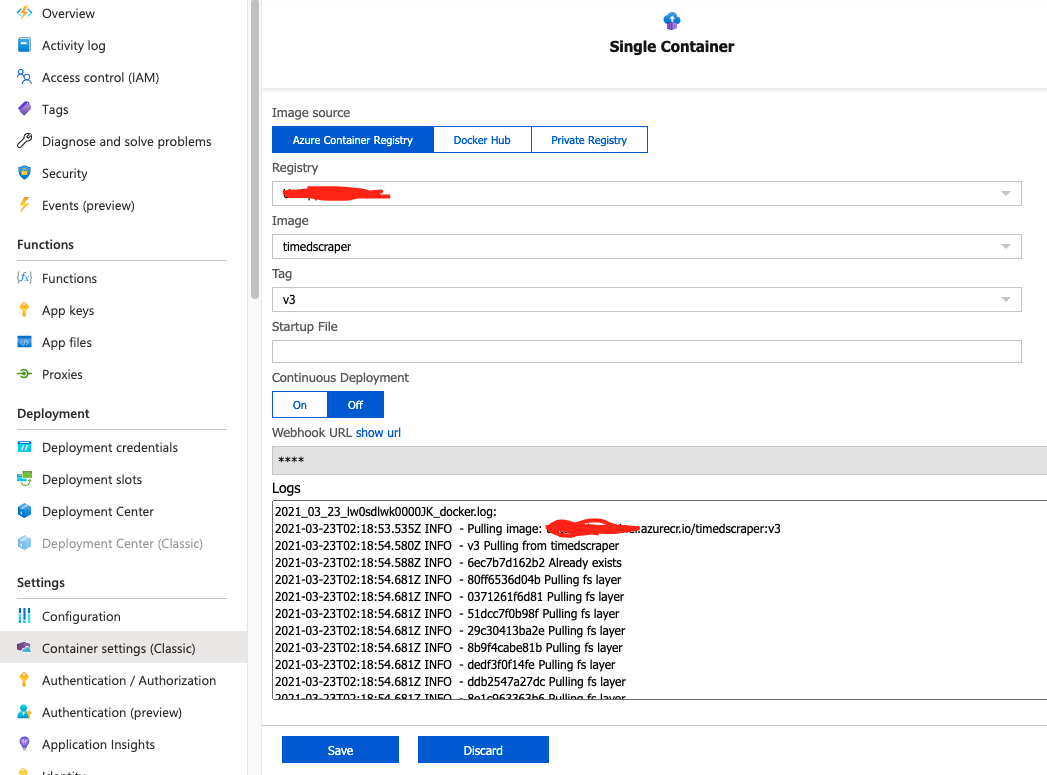
Wanneer dit ingesteld is zal de Docker container worden opgehaald en gerund. Indien je code niet werkt is het aan te raden om de Docker container even lokaal te bouwen en testen. Vergeet ook niet eventuele environment variables toe te voegen. Dit kan in de Azure Functions onder ‘Settings>Configuration’, eventueel nog met behulp van een Keyvault.
Heb je vragen naar aanleiding van deze tutorial of wil je sparren over welke data science technieken het meest geschikt zijn voor jouw project, neem gerust contact met ons op. Succes met scrapen!
