

De Floating Farm in Rotterdam is de eerste drijvende boerderij ter wereld. De prioriteiten zijn dierenwelzijn, circulariteit, duurzaamheid en innovatie. Voor ons eens interessant om te onderzoeken wat je allemaal kan met computer vision op een boerderij. Het doel? Inzicht krijgen in het voerproces om het proces te kunnen optimaliseren en uiteindelijk verspilling van voer tegen te gaan.
Aan de slag, start verzamelen data
Om met computer vision aan de slag te kunnen gaan hebben we beelden nodig. We zijn gestart met het verzamelen van foto’s van de voerplekken voor de koeien. We hebben Hikvision camera’s geïnstalleerd, want dit sluit goed aan op de integratie met Python. Het bijzondere aan dit project is de inzet van twee verschillende camerahoeken. We hebben hierdoor data kunnen verzamelen vanuit twee perspectieven, om ons computer vision model meteen een extra uitdaging erbij te geven.


De twee verschillende camerahoeken
Tijd om te classificeren
Nu we beelden verzamelen is het tijd om de beelden te gaan classificeren, a.k.a image classification. Maar wat is image classification? Met image classification leren computers afbeeldingen in verschillende categorieën te plaatsen. Dit gebeurt met machine learning, zoals deep learning, die patronen en kenmerken kunnen herkennen. Het getrainde model kan zo nieuwe onbekende afbeeldingen analyseren en vervolgens voorspellen bij welke categorie ze horen.
Voor de techneuten onder ons. Ik hoor je denken… Heb je nog nagedacht over masking technieken? Ja, zeker, alleen image classification was beter geschikt voor de complexe omgeving van een drijvende boerderij. Daarnaast was het efficiënter en robuuster.
In dit geval moet het model drie categorieën goed kunnen onderscheiden.
- Voldoende voer
- Onvoldoende voer
- En moet worden aangeveegd



Door de classificatie kan de computer afbeeldingen van voerplekken voor de koeien analyseren en beoordelen wat er moet gaan gebeuren.
Als er genoeg voer is, wordt het gekenmerkt als voldoende voer. Er is geen actie vereist. Is er te weinig of geen voer dan wordt het herkend als onvoldoende voer. Er moet voer bij. Is er veel voer, maar de koeien kunnen er niet bij, dan wordt het gekenmerkt dat er aangeveegd moet worden.
Data labeling
Elke foto die is verzameld, moet worden gelabeld om de drie categorieën voldoende voer, onvoldoende voer en er moet worden aangevuld te identificeren. Dit labelingsproces is essentieel voor het trainen van het image classification-model. Dit moet heel nauwkeurig en consistent gebeuren voor de betrouwbaarheid van het model.
Modellen trainen
We hebben verschillende machine learning-modellen onderzocht om dit zo secuur mogelijk te kunnen doen. Het CNN-model pastte het beste hierbij. Onze data bestaan uit twee verschillende camerahoeken en hierdoor hebben we drie modellen afzonderlijk getraind. Eén voor elke camerahoek en het derde model combineert de data van beide hoeken.
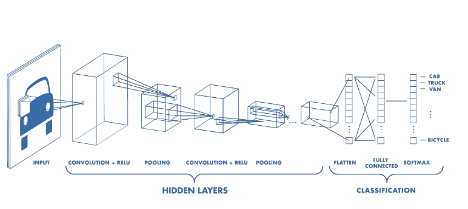
Architectuur van een CNN
Meten is weten
Tijdens het hele proces hebben we alles in metrics bijgehouden om de presentaties van het model te kunnen beoordelen. We keken naar dingen zoals hoe vaak het gelijk had, hoeveel keer het de mist in ging (accuracy, precision, recall en F1-score zijn gemeten), alles om te kunnen testen hoe effectief het model is om de voerstatus te identificeren.
Is computer vision iets voor op de boerderij?
De Floating Farm is een perfect voorbeeld van hoe innovatie en technologie kunnen worden ingezet om duurzaamheid, efficiëntie en productiviteit in de landbouw te stimuleren. Het gebruik van image classification is niet alleen een slimme manier om voer voor koeien te beheren, maar het opent ook de deur naar een nieuwe wereld van mogelijkheden voor de landbouwsector.
Alle drie de modellen presteren gemiddeld gezien boven de 85% nauwkeurigheid bij het classificeren van de voerstatus. Opvallend is dat de modellen die zijn getraind met gegevens van afzonderlijke camerahoeken iets beter presteren dan het gecombineerde model.
Hier zijn enkele testvoorbeelden waarop het gecombineerde model voorspellingen heeft gedaan. Onder elke afbeelding staat het zekerheidspercentage van het model.



99.99% voldoende voer
100% onvoldoende voer
99.46% moet worden aangeveegd
Deze innovatieve aanpak kan veel voordelen voor de moderne landbouw hebben. Het maakt het proces veel efficiënter, vermindert voerverspilling en handmatig werk wordt hier verminderd. Belangrijker nog, het zorgt ervoor dat er altijd voer beschikbaar, wat de gezondheid en productiviteit van de koeien bevordert. Een mooie stap waarin slimme technologie de agrarische sector vooruithelpt. Oftewel computer vision op een boerderij? Absoluut.
Heb jij een leuk idee om de agrarische sector vooruit te kunnen helpen? Neem contact met ons op en wij denken graag mee.


