

Deze hond bestaat niet
Het genereren van mensen, dieren, b&b’s, of kunst door AI is een van de vele interessante ontwikkelingen op het gebied van machine learning. De neurale netwerken die gebruikt zijn op deze websites vallen in de categorie Generative Adverserial Networks, ook wel een GAN genoemd. Het idee van een GAN is ontwikkeld in 2014 door Ian Goodfellow, toenmalig research scientist bij Google. In zijn paper vergelijkt hij de werking van een GAN met het kat en muis spel tussen geldvervalsers en de politie. Het doel van de vervalsers is om zo goed mogelijk geld na te maken, terwijl de politie zoveel mogelijk nep geld wilt opsporen. Door het herkennen van nep geld wordt de politie beter in het opsporen, en door de ‘feedback’ die de vervalsers daarvan terug krijgen worden zij weer beter in het produceren van nep geld. Dit spel gaat verder totdat uiteindelijk het nep geld niet meer van echt te onderscheiden is. Het producerende vermogen van de GAN komt dan ook door geldvervalsers, maar dit is niet mogelijk zonder de feedback van de politie. In een GAN zijn de vervalsers en de politie twee neurale netwerken die in een feedbackloop van elkaar leren.

Naast het genereren van afbeeldingen kunnen GANs ook voor andere praktische doeleinden gebruikt worden. Enkele voorbeelden zijn: [weghalen van visuele ruis (zoals regen) in afbeeldingen, opschalen van lage resolutie afbeeldingen, herstellen van beschadigde fotos, genereren van een persoonlijke emoji op basis van een foto van een persoon (b.v. de bitmoji op snapchat), opschalen van datasets, en nog vele andere toepassingen. Hoewel deze blog zich focust op de generatieve kracht van GANs, is het wel belangrijk om te benoemen dat er veel meer gedaan kan worden met GANs dan alleen maar afbeeldingen genereren.Als je het leuk vind om visuele dingen te maken maar niet creatief bent zijn dit soort netwerken perfect. Het belangrijkste ingrediënt zijn duizenden afbeeldingen om het netwerk op te trainen. Voor mijn eerste duik in de wereld van GAN’s kwamen de data van de Kaggle competitie Generative Dog Images. Naast de data waren de discussies daar ook een fijne bron van inspiratie tijdens het ontwikkelen van een GAN. Maar voordat de code ingedoken kon worden is het goed om te weten hoe deze, bijna magische, neurale netwerken er onder de motorkap uit zien.
Wat is een GAN?Simpel gezegd is een GAN een neuraal netwerk dat de distributie van een gegeven dataset leert en het daardoor mogelijk maakt om nieuwe samples uit die dataset te genereren. In deze blog gaat het over het genereren van afbeeldingen, maar GAN’s kunnen van alles genereren, van tekst tot audio.De architectuur van een GAN kan opgedeeld worden in twee delen: de generator en de discriminator. De generator is een netwerk dat, gegeven een zogenaamde ‘noise vector’, een nep sample uit de dataset genereert. De noise vector (z), is een arbitrair lange 1-dimensionale vector met willekeurige getallen. Vaak is deze vector 100 lang, met de getallen getrokken uit een standaard normaal verdeling. De discriminator is een netwerk die werkt als een standaard binaire classifier. De discriminator krijgt tijdens het trainen echte samples uit de dataset en neppe gegenereerde samples te zien. Deze worden vervolgens als echt of nep geclassificeerd. Op basis van die feedback past de generator zijn gewichten aan om betere samples te genereren, die de discriminator hopelijk als ‘echt’ ziet.Het proces van afwisselend genereren en classificeren is hoe een GAN zichzelf traint, dit ziet er in pseudocode als volgende uit:

Hier is te zien dat de GAN in 2 stappen getraind wordt. De eerste stap is het trainen van de discriminator, in deze stap worden ook alleen de gewichten van de discriminator geüpdatet. De generator blijft hetzelfde in deze stap. In de tweede stap genereert de generator nieuwe samples, welke door de discriminator geclassificeerd worden. Op basis van die classificatie word de loss van de GAN berekend, en worden de gewichten van de generator geüpdatet. De backpropagation die in deze stap via de discriminator naar de generator gaat is ook de reden dan de GAN, ondanks dat het uit 2 netwerken bestaat, 1 netwerk is. De netwerken moeten met elkaar verbonden zijn om de gewichten van de generator te kunnen updaten.Om wat technischer te worden kunnen we de discriminator (D) en de generator (G) definiëren als een differentieerbare functie. Functie D(x) representeert de kans dat input x een echt sample is, het doel van het netwerk is de kans dat deze functie een goede classificatie geeft te maximaliseren. Tegelijkertijd is functie G(z) een mapping van noise vector z naar een datapunt met als doel om 1 - D(G(z)) te minimaliseren, of in normale taal: het minimaliseren van de kans dat een gegenereerd sample als nep wordt gezien door D. Deze speling tussen D en G is een minimax spel en is uit de drukken in de volgende functie:
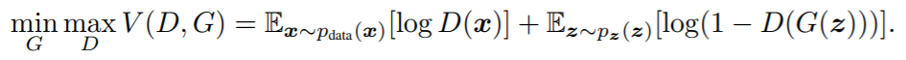
Bron
Tot nu toe is de architectuur van D en G nog niet uitgebreid beschreven. Dit is omdat deze functies voor elk soort GAN er anders uit zien. Hoe kunnen deze functies er uit zien en wat heeft dat voor invloed op de output van de GAN?
GAN architecturen
Zoals bij elk neuraal netwerk zijn er vele architecturen mogelijk, dit is bij GANs niet veel anders. Van de originele gan die alleen multilayer perceptrons gebruikte, tot de BigGAN die gebruik maakt van technieken zoals attention maps, skip-z connecties en meer. Zoals te zien in de afbeelding is er veel voortgang geweest in de kwaliteit van de output van een GAN. Ondanks het grote verschil in kwaliteit hebben beide netwerken nog steeds dezelfde generator/discriminator structuur, alleen heeft de BigGAN een stuk geavanceerdere discriminator en generator.

Output van de originele GAN (links) en die van de BigGAN (rechts)
Een ander voorbeeld van een netwerk met hoge kwaliteit output is de StyleGAN. Dit netwerk heeft ook de klassieke generator discriminator structuur maar door een speciale manier van trainen is dit netwerk geschikt voor de output van hoge resolutie afbeeldingen. Meer informatie over andere generatieve netwerken, waaronder de StyleGAN is in deze blog te vinden.Ergens tussen de originele GAN en de BigGAN zit de Deep Convolutional GAN (DCGAN). Dit netwerk maakt gebruik van convolutional layers in de discriminator en generator. Dit netwerk kan, als het goed getraind is, met de relatief simpele architectuur toch goede output geven.De generator en de discriminator van de DCGAN zijn allebei convolutional networks, waarbij de discriminator een spiegelbeeld is van de generator. In de afbeelding hieronder is te zien hoe de architectuur van het generator netwerk er uit ziet. De discriminator is het spiegelbeeld generator met als verschil dat het eindigt met een sigmoid node die een voorspelling doet of de input echt is of nep.Een belangrijk detail is dat de DCGAN geen gebruik maakt van pooling of upscaling lagen, iets wat wel gebruikelijk is bij een convolutional network. In plaats van deze lagen worden (de)convoluties gedaan met een stride (stapgrootte) van 2, hierdoor leert het netwerk de transformaties, dit zorgt voor betere output. Verdere richtlijnen genoemd door de bedenkers van de DCGAN zijn:
- Learning rate van 0.0002 voor de generator en discriminator
- Gebruik van batch normalisatie
- Geen gebruik maken van fully connected lagen
- ReLU activatie functies voor de generator
- Leaky ReLU activatie voor de discriminator
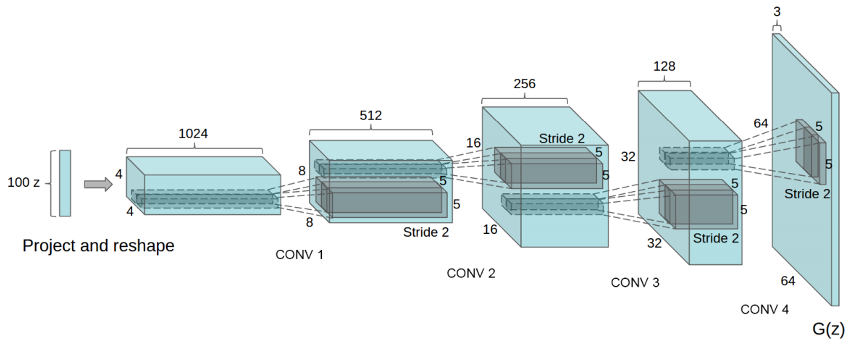
Met deze richtlijnen en een idee van hoe je de netwerken inricht klinkt het alsof het trainen zo gedaan is. Dit is jammer genoeg niet het geval, GANs staan er om bekend dat het erg lastig is om ze te trainen. Wat kan er allemaal fout gaan en hoe los je dat dan op?
Hoe train je een GAN?
Het trainen van een GAN is een delicaat proces waarbij veel fout kan gaan. Het doel is dat de discriminator en de generator in balans blijven, de een mag niet “sterker” worden dan de ander. In de optimale situatie zijn de generator en de discriminator in een Nash Equilibrium. Dit is een term uit spel theorie die zegt dat een speler in een spel zijn strategie niet aanpast, ongeacht wat de andere speler doet. Dit equilibrium is erg lastig om te bereiken, wat je eerder zult zien is een schommeling tussen de sterkste speler. Dit is niet erg want ook in deze situatie kan een GAN goede output genereren.

Checkerboard artefacten (links), [kleurrijke grids (midden), mode collapse (rechts)
Enkele dingen die fout kunnen gaan tijdens het trainen van een GAN zijn hierboven te zien. Dit waren persoonlijk ook de drie grootste problemen tijdens het ontwikkelen van een GAN.Checkerboard artefacts zijn een schaakbord achtig patroon van (groepen) pixels die donkerder of lichter zijn dan hun buren. Deze artefacten ontstaan tijdens de deconvolutie. Door een verkeerde combinatie van kernel grootte en stap grootte wordt het geleerde filter meerdere malen op dezelfde pixel toegepast, waardoor de waarde van die pixel dubbel veranderd ten opzichte van zijn buren. Gelukkig is er een simpele oplossing voor dit probleem: het gebruik van een kernel grootte die een product is van de stap grootte. Hierdoor gaat het filter precies 1 keer over elke pixel en worden de artefacten voorkomen. Als het niet mogelijk is om deze combinatie van stap- en kernel grootte te gebruiken is een andere oplossing om in de laatste convolutie laag een filter met stap grootte 1 te kiezen, hierdoor worden de artefacten ook verminderd. Meer informatie over deze artefacten is te vinden in dit artikel van distill.Als de output van een GAN er uit ziet als een kleurrijk grid dan is er waarschijnlijk sprake van een te grote onbalans tussen de learning rate van de generator en die van de discriminator. De GAN maakt output zoals deze als de generator te snel leert, of de discriminator te langzaam. Dit is ook te zien aan de loss van de generator; als deze erg op en neer schommelt dan moet er aan de learning rates gesleuteld worden. De loss van de discriminator en de generator moeten ongeveer hetzelfde patroon vertonen, waar de generator loss meestal iets hoger ligt dan die van de discriminator.Het grootste probleem in het trainen van een GAN is (partial) mode collapse. In dit geval heeft de output van de GAN een lage variatie en lijkt alles op elkaar. Dit is bijvoorbeeld te zien in de rechter afbeelding, waar, voor elke mogelijke input van z, een 6 als output gegenereerd wordt. Dit gebeurt als de generator ‘ontdekt’ dat 1 bepaalde output altijd als echt gezien wordt door de discriminator. In dit geval krijgt de generator positieve feedback en blijft het die output genereren. Dit is logisch want het doel van de generator is om de discriminator te slim af te zijn. In de literatuur is men er ook nog niet uit wat nou de precieze oorzaak van een mode collapse is, maar wel zijn er vele oplossingen bedacht. De simpelste oplossing is het toevoegen van ruis in de labels voor de discriminator, hier later meer over.Een andere, complexere, manier om mode collapse tegen te gaan is de unrolled GAN. In deze architectuur wordt voor elke training stap de generator geüpdatet door niet alleen de huidige discriminator, maar ook door de discriminator N stappen in de toekomst. Door deze betere discriminator output leert de generator ook beter en blijft de output divers.Nog een paar kleine aanpassingen aan de GAN die erg geholpen hebben waren het flippen van de labels die de discriminator in gingen, en het toevoegen van ruis aan diezelfde labels. Het omwisselen van de labels (1 voor nep, 0 voor echt) zorgt ervoor dat de generator sneller leert in het beginstadium van het trainen. Het toevoegen van ruis houd in dat ten eerste de labels ‘soft’ zijn, dus geen harde 1 of 0 maar willekeurige waardes tussen de 1 en 0.9 of 0 en 0.1. Als tweede hadden de labels een 5% kans om geflipt te worden, dus een 1 werd een 0 en omgekeerd. Dit zorgt ervoor dat de kans op een mode collapse kleiner wordt, en was voor de gekozen datasets genoeg om mode collapse te voorkomen.Als laatste is ook batch normalization gebruikt in de discriminator en spectral normalization in de discriminator en de generator. De batch normalisatie zorgt voor stabieler trainen in diepe netwerken, en de spectral normalization zorgt voor betere, scherpere output.
Resultaat
Met al deze kennis en tips op zak was het tijd om met het echte werk te beginnen. Als eerste werd de GAN getest met de ‘hello world’ van de machine learning datasets: de MNIST getallen. Dit is een relatief simpele dataset om mee te beginnen omdat hij zwart wit is, en een lage variatie vertoont. Om gelijk te blijven aan de DCGAN paper is de data opgeschaald naar van 28 bij 28 naar 64 bij 64 pixels. De MNIST data is een goeie dataset om mee te beginnen, zonder al te veel moeite was het gelukt om duidelijke output te krijgen, zoals hier onder te zien is.

Omdat de MNIST dataset zo voor de hand liggend en niet heel interessant is, is de GAN ook getraind op tekeningen van schapen uit Googles Quick, draw! dataset. Geïnspireerd door het boek ‘Dreaming of Electric Sheep’, waar 10.000 door een GAN gegenereerde tekeningen van schapen in staan. Hieronder een afbeelding met plaatjes uit de dataset en die gegenereerd door de GAN.

Tekeningen uit Quick, Draw data (links) en gegenereerde tekeningen (rechts)
Zoals te zien is lukt het de GAN goed om data te genereren voor zwart-wit data. Echt interessant wordt het als we gaan trainen op kleuren afbeeldingen, dus 3D data door de meerdere kleur kanalen. Omdat de extra dimensie van kleur meer complexiteit met zich mee brengt is het voor de GAN ook een stuk lastiger om realistische data te genereren. Ook is het kiezen van hyperparameters lastiger, omdat veel parameter combinaties eindigen in de kleurrijke grids die eerder besproken zijn.Een simpele kleuren dataset om mee te beginnen is de Google StreetView House Number (svhn) dataset. In deze dataset staan close-up afbeeldingen van huisnummers met variatie in kleur, lettertype, en de hoek waarop de foto gemaakt is. Om goede resultaten te krijgen op deze dataset moest al veel aan de learning rates van de discriminator en generator gesleuteld worden. Uiteindelijk bleken learning rates van 0.001 en 0.0001 voor de discriminator en generator respectievelijk het best te werken op de datasets met kleur. Hieronder is een sample uit de dataset en de gegenereerde afbeeldingen te zien.

SVHN dataset (links) en gegenereerde samples (rechts)
[divider line_type="No Line" custom_height="30″]
Na het langzaam opwarmen op deze oefen datasets was het tijd om te beginnen aan de dataset waar de GAN uiteindelijk voor gemaakt is: de Stanford Dogs dataset waar de Kaggle competitie om draaide. Deze dataset is een stuk complexer vergeleken met de svnh data. Het gaat hier om een grote variatie aan honden (kleur, ras, houding) in een grote variatie aan omgevingen. Deze complexiteit bleek jammer genoeg te lastig voor het netwerk om te leren, de output is makkelijk van echt te onderscheiden. Ondanks die complexiteit heeft de output zeker wel wat weg van een hond. Na dagen lang trainen en experimenteren met learning rates kwam er dan toch een netwerk uit dat goede output gaf. Het uiteindelijke netwerk duurde 9 uur om te trainen met learning rates van 0.0001 en 0.0003 voor de discriminator en generator respectievelijk. Een sample van de output van het netwerk is hieronder te zien.

Enkele honden gegenereerd door de GAN
Interessant is dat de GAN sommige poses goed kan representeren, bijvoorbeeld een kop die omhoog kijkt of een zijaanzicht van een hond. Ook was het interessant om te zien dat de kleuren en patronen op de vacht goed geleerd was, en daar ook goeie variatie in is te zien.
Hoe verder?
De output van de GAN is goed genoeg om er honden in te zien, maar er is nog veel ruimte voor verbetering. Zoals al eerder gezegd is de Stanford Dogs dataset complex omdat er veel variatie in de data zit. Een mogelijke oplossing is het gebruiken van een Conditional GAN (CGAN). Bij de CGAN krijgen de generator en discriminator naast hun gebruikelijke input ook een class label mee. Deze class labels worden mee gegeven in de vorm van bijvoorbeeld een embedding of een one-hot vector. De class labels worden dan door een fully connected laag naar het juiste formaat gebracht, waarna ze samengevoegd worden met de originele input. Het samengevoegde geheel kan dan door de discriminator of generator gehaald worden. De class labels kunnen bijvoorbeeld, in het geval van de Stanford Dogs dataset, het ras van de hond zijn. De labels zouden echter ook een compleet andere feature van de afbeelding kunnen representeren, zoals bijvoorbeeld de kleur van de hond, de hoek waarop de foto is genomen, de achtergrond, etc.
Een voordeel van de CGAN is dat het netwerk door de labels beter onderscheid kan maken in de variatie in de gegeven dataset, waardoor de output van hogere kwaliteit is. Daarnaast maakt de CGAN architectuur het ook mogelijk om output van alleen een bepaalde class te genereren, iets wat voor een normale GAN erg lastig is. Het grootste nadeel van het gebruik van een CGAN is dat je van een unsupervised naar een supervised probleem gaat, en er dus een gelabelde dataset nodig is.
Een andere oplossing is gebruik maken van een Wasserstein GAN (WGAN). Een WGAN vervangt de discriminator met een zogenaamde critic. In plaats van een harde ‘echt of nep’ voorspelling geeft de critic een score van echtheid. Deze score moet laag zijn voor echte input en hoog voor neppe input, en is niet gebonden tussen 0 en 1. De WGAN gebruikt ook een nieuwe loss functie: de Wasserstein loss. De precieze werking van de Wasserstein loss functie in de WGAN is te complex om hier kort uit te leggen, een uitgebreide uitleg is hier te vinden. Een voordeel van de WGAN is dat de critic te optimaliseren valt zonder rekening te houden met wat dat betekent voor de generator. In een normale GAN betekent een perfecte discriminator dat de generator niks leert, maar met een perfecte critic valt de generator alsnog te verbeteren. Dit is te zien in de afbeelding hieronder. In deze afbeelding worden de gradients van een perfecte critic en discriminator met elkaar vergeleken in het onderscheiden van twee (hypothetische) verdelingen. Zoals te zien zorgt de sigmoid functie van de discriminator voor slechte gradients, terwijl de lineaire activatie van de critic zorgt voor een gradient waar de generator nog van kan leren.
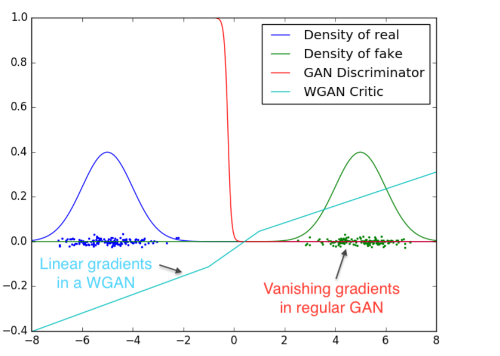
Deze eigenschap van de critic zorgt ervoor dat de WGAN niet meer de balans tussen generator en critic hoeft te houden, waardoor de WGAN robuuster wordt en minder snel zal falen. Daarnaast zorgt deze robuustheid ervoor dat er meer variatie mogelijk is in architectuur en learning rates van generator en critic/discriminator zonder dat de output nergens op lijkt. Een laatste voordeel is dat de WGAN ook een mode collapse kan voorkomen.
Natuurlijk is de beste manier om hoge kwaliteit output te krijgen het gebruik maken van een state-of-the-art architectuur , zoals de eerder genoemde StyleGAN of BigGAN. Deze architecturen zijn erg complex (maar niet onmogelijk) om zelf te implementeren. Daarnaast is er ook goede hardware nodig om deze netwerken te trainen, zo had StyleGAN 1 week op 8 GPU’s nodig. Voor een ‘echt’ project is echter wel interessant om naar deze oplossingen te kijken.
Conclusie
Na het lezen van vele papers en blogs over het ontwikkelen van GANs is het gelukt om een werkende variant van de DCGAN te ontwikkelen. Dit netwerk slaagde erin om de distributie van datasets met een relatief lage complexiteit vast te leggen en daar nieuwe data uit te genereren. Jammer genoeg waren de Stanford Dogs te complex voor de huidige implementatie van het netwerk.
Ondanks al het onderzoek voor het ontwikkelen bleek het al snel dat er geen one size fits all oplossing is voor elke dataset; er moest altijd wel wat gesleuteld worden aan de learning rates voordat de output naar wens was. Er waren gevallen waar een verandering van 0.0001 het verschil betekende tussen goeie output en de kleurrijke grids. Dit maakte het trainen van een GAN lastig, maar ook een goede exercitie in het lezen en interpreteren van de losses van het netwerk.
Het onderzoek doen naar en het ontwikkelen van een GAN was een leerzame ervaring, en het was erg gaaf om te zien dat je met een relatief simpel netwerk toch mooie output kon genereren. Jammer genoeg was het de GAN niet gelukt om goed de anatomie van een hond te leren, zoals te zien is in de output. Ondanks dat waren de resultaten goed genoeg voor een plek in de top 47% van de Kaggle competitie, en toen bovenstaande afbeelding in Word geplakt werd de beschrijving “Afbeelding met hond” gegeven. Misschien zijn de honden niet goed genoeg om een mens in de maling te nemen, maar de algoritmes van Microsoft worden in ieder geval wel om de tuin geleid.


