

Wat zijn de mogelijkheden van GenAI, Large Language Models (LLM’s) voor de interne organisatie? Hoe implementeren we een LLM doelmatig voor organisaties. Niet alleen als ‘nice to have’, maar om er zeker van te zijn dat ze met de toepassing efficiënter en effectiever kunnen werken. Oftewel een stap vooruit.
Er zijn veel processen die tijd kosten die efficiënt door een LLM uitgevoerd kunnen worden. We hebben het al eerder gehad over een LLM voor je knowledge management. Een goed voorbeeld van hoe je je knowledge base op een efficiënte manier toegankelijk kan maken voor je organisatie. In deze blog neem ik, Dave Meijdam (Data Scientist), je mee en gaan we in op de toegevoegde waarde van een interne LLM in combinatie met RAG voor Fokker.
Fokker case uitgelicht
Stel je voor dat een Program Manager bij Fokker op zoek is naar specifieke details van een contract dat enkele jaren geleden is opgesteld. In plaats van door diverse mappen en documenten te bladeren, kan hij/zij simpelweg een vraag stellen aan de LLM. Zoals "Wat zijn de belangrijkste voorwaarden van het contract met leverancier X voor project Y?". De LLM, ondersteund door RAG, haalt dan het relevante document op en geeft een samenvatting van de gevraagde informatie. Dit versnelt niet alleen het proces, maar zorgt ook voor correcte en herleidbare informatie.
Een ander voorbeeld is het Customer Support team dat snel informatie nodig heeft over de garantievoorwaarden van een specifiek vliegtuigonderdeel. Met een gecentraliseerde kennisbank en een LLM kunnen ze eenvoudig vragen stellen als "Wat zijn de garantievoorwaarden voor onderdeel Z?". Je krijgt direct een nauwkeurig antwoord op basis van de meest recente en relevante documenten.
In een ideale situatie heeft Fokker een centrale kennisbank waar iedereen met vragen over processen en afspraken terecht kan. Deze situatie kan gecreëerd worden met een LLM-implementatie, gecombineerd met RAG en een knowledge base. Bij deze oplossing is het belangrijk dat de organisatie de antwoorden van de LLM kan valideren. Om zo vertrouwen te creëren en eventuele fouten makkelijk op te sporen. Voorbeelden hiervan zijn instructies om altijd de naam van het document en het paragraafnummer te benoemen bij een antwoord. Of om inzicht te krijgen in wat voor stukken tekst er worden opgehaald door het RAG-systeem. DSL heeft een deel van dit systeem bij Fokker geïmplementeerd, genaamd Anthony Chat.
De kracht van Retrieval-Augmented Generation (RAG)
Een van de veelbelovende technologieën op dit gebied is RAG. RAG combineert een generatief model, zoals een LLM, met een retrieval system. Dit systeem zoekt naar relevante documenten of informatie uit een vooraf gedefinieerde knowledge base. Daarna gebruikt de LLM deze informatie om een accuraat antwoord te genereren. Zo zijn de antwoorden niet alleen contextueel relevant, maar ook feitelijk juist. Omdat ze gebaseerd zijn op de meest recente en specifieke informatie uit de knowledge base.
Een knowledge base is een georganiseerde verzameling van informatie die eenvoudig doorzoekbaar is. Binnen een organisatie als Fokker bestaat de kennisbank uit juridische documenten, contracten, handleidingen, technische specificaties en andere relevante bedrijfsdocumenten. Door deze informatie te centraliseren, kunnen medewerkers snel en efficiënt de nodige informatie vinden. Zonder door meerdere mappen en documenten te hoeven zoeken. Deze documenten worden opgeslagen in een vector store.
Een vector store is een database die speciaal is ontworpen om tekstinformatie op te slaan en te doorzoeken op basis van vectoren. In plaats van traditionele zoekmethoden die werken met trefwoorden, gebruikt een vector store numerieke representaties (vectoren) van de tekst. Deze vectoren worden gegenereerd door een embeddingsmodel, dat elke zin of document omzet in een hoogdimensionale vector.
RAG-proces uitgelegd
Het RAG-proces nog even in het kort uitgelegd:
Embedden van Documenten: Elk document in de knowledge base wordt opgedeeld in kleinere delen (chunks). Deze chunks gaan vervolgens door een embeddingsmodel, dat ze omzet in vectoren. Deze vectoren geven de semantische betekenis van de tekst weer, waardoor vergelijkbare teksten dicht bij elkaar liggen in de vectorruimte.
Opslaan van Vectoren: De gegenereerde vectoren worden opgeslagen in de vector store samen met de bijbehorende documentinformatie (metadata).
Zoeken met Vectoren: Wanneer een gebruiker een vraag stelt, wordt de vraag eveneens omgezet in een vector door hetzelfde embeddingsmodel. Deze vraagvector wordt dan vergeleken met de vectoren in de vector store om de meest relevante chunks te vinden. Deze vergelijkingen worden vaak gedaan met behulp van technieken zoals cosine similarity, die meet hoe dicht vectoren bij elkaar liggen.
Retrieval van Documenten: De meest relevante chunks worden opgehaald en gebruikt door de LLM om een accuraat antwoord te genereren.
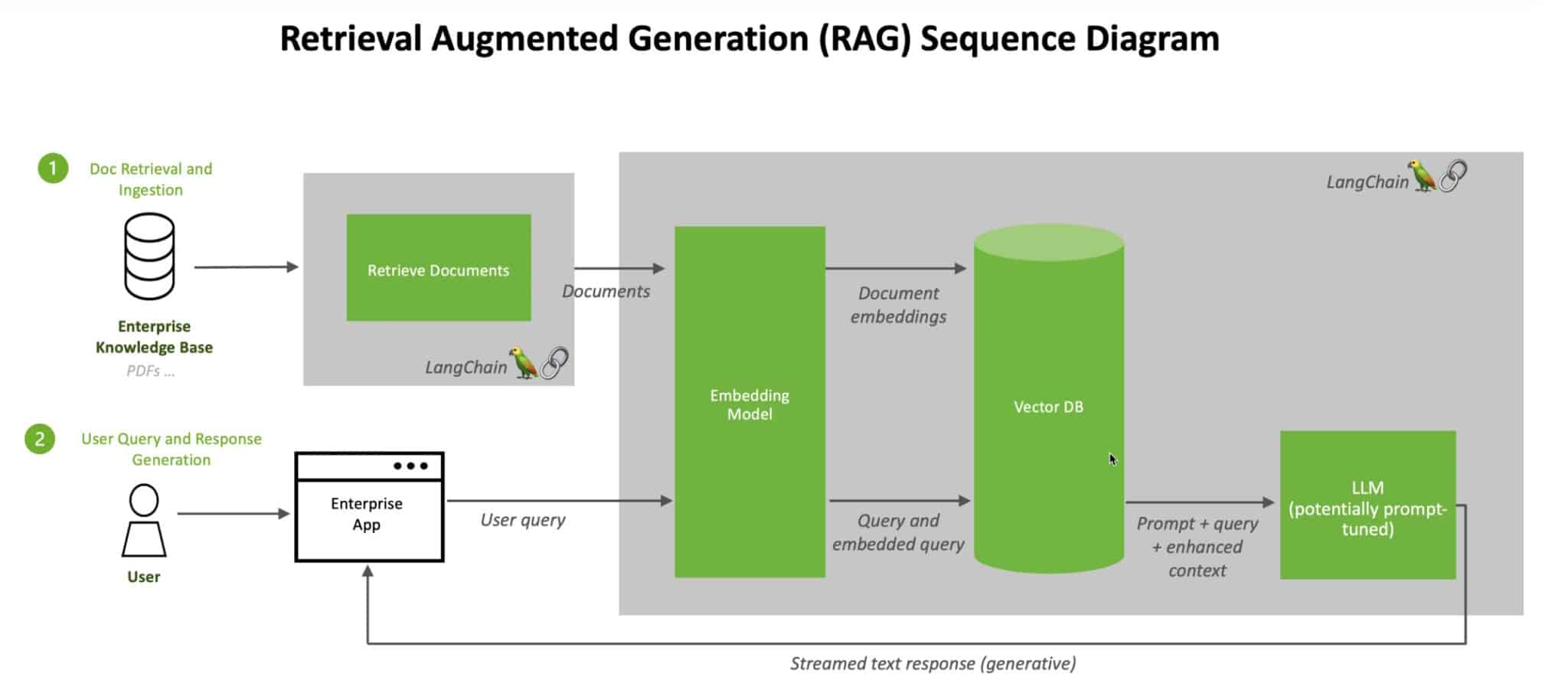
Voordelen van interne LLM’s in combinatie met een RAG Implementatie en een Vector Store als Knowledge Base
De implementatie van GenAI oftewel interne LLM’s in combinatie met RAG en een vector store als knowledge base kan aanzienlijke voordelen opleveren voor Fokker:
Precisie en Relevantie: Vectorgebaseerd zoeken zorgt ervoor dat de meest semantisch relevante chunks worden opgehaald, zelfs als ze niet exact dezelfde trefwoorden bevatten als de zoekvraag.
Schaalbaarheid: Een vector store kan gemakkelijk omgaan met grote hoeveelheden data en kan snel zoeken, zelfs in een zeer grote knowledge base.
Contextbewuste Zoekopdrachten: Doordat vectoren de semantische inhoud van de tekst representeren, kan het systeem complexe en contextuele vragen beter begrijpen en beantwoorden.
Efficiëntieverbetering: Door een knowledge base te hebben, kunnen medewerkers sneller toegang krijgen tot de benodigde informatie. Dit vermindert de tijd die besteed wordt aan het zoeken naar documenten en verbetert de algehele productiviteit.
Accurate Informatie: Een LLM dat gebruikmaakt van RAG zorgt ervoor dat antwoorden gebaseerd zijn op de meest relevante informatie uit de knowledge base. Dit vermindert de kans op fouten en inconsistenties in de verstrekte informatie.
Kennisbehoud: Het centraliseren van informatie helpt bij het behouden van kennis binnen de organisatie, vooral wanneer medewerkers vertrekken of van rol veranderen. Dit zorgt voor continuïteit en vermindert de afhankelijkheid van individuele kennisdragers.
Learnings & toekomst
Het realiseren van een RAG-systeem gaat uiteraard niet zonder uitdagingen. Zo kwam vanuit de organisatie de vraag om tientallen vragen tegelijk over een document te stellen, om snel veel specifieke informatie op te halen. Met de initiële RAG-implementatie werkte dit niet optimaal: doordat er een generieke embedding van de input werd gemaakt, konden niet alle relevante chunks worden teruggevonden om alle vragen te beantwoorden. Met als resultaat dat de LLM een deel van de vragen kon beantwoorden en niet alle vragen. Om dit op te lossen hebben we een tussenstap toegevoegd: eerst wordt de gebruikersinput, wanneer nodig ontleed in meerdere specifieke vragen. Vervolgens wordt elke vraag één voor één beantwoord, en alle antwoorden worden als chunks gebruikt voor het uiteindelijke antwoord.
Een andere uitdaging is dat contracten op elkaar kunnen lijken, zeker wanneer ze zijn opgedeeld in chunks in een vector store. Het is absoluut ongewenst dat informatie van een andere klant per ongeluk als chunk wordt gebruikt in het antwoord van de LLM. Om dit te voorkomen, is het essentieel om documenten en chunks van duidelijke metadata te voorzien. Denk bijvoorbeeld aan metadata die aangeeft over welke klant het gaat of, in het geval van Fokker, om welke vliegtuigonderdelen het specifiek gaat. Om dit risico op dit moment te vermijden, moet de gebruiker handmatig een document selecteren of uploaden. In de toekomst willen wij een robuuste knowledge base opzetten, waardoor het handmatig selecteren van het juiste document overbodig wordt en daarmee de eerder benoemde ideale situatie wordt gecreëerd.
Conclusie
De integratie van interne LLM’s en RAG binnen Fokker biedt een innovatieve oplossing voor de uitdagingen van gedistribueerde informatieopslag. Het verbetert de efficiëntie van verschillende taken, zorgt voor consistente en accurate informatie, ondersteunt betere besluitvorming, en helpt bij het behoud van kennis binnen de organisatie. Door deze technologie te omarmen, kan Fokker niet alleen de dagelijkse werkzaamheden vereenvoudigen, maar ook de algehele concurrentiepositie versterken. In een tijd waarin informatie de sleutel is tot succes, bieden interne LLM’s en RAG de tools die Fokker nodig heeft om voorop te blijven lopen. Wil jij ook voorop lopen? Neem contact met ons op.


