

Sinds de opkomst van ChatGPT kan niemand er meer om heen: ‘Large Language Models’* (LLM’s) are here to stay’. Verschillende technologiebedrijven hebben geavanceerde LLM’s ontwikkeld. Bekende voorbeelden zijn ChatGPT van OpenAI, LLaMA van Meta en laMDA van Google. Nu hoor ik je denken: ‘Heel interessant allemaal, maar wat moet ik er zelf mee?’
In de praktijk blijkt dat het vinden van een geschikte business case voor het toepassen van LLM-oplossingen voor veel organisaties en ondernemers een grote uitdaging is. In deze blog leggen we uit waarom je LLM’s wilt gaan gebruiken voor kennisdeling binnen jouw organisatie. We lichten de uitdagingen rondom het fenomeen knowledge management toe en de potentiële rol van LLM’s.
Wat is Knowledge management?
Knowledge management wordt gezien als het opslaan, organiseren, beheren en delen van kennis binnen een organisatie. Het draagt in grote mate bij aan het succes van een organisatie: wanneer kennis niet gemakkelijk toegankelijk is, kan dit destructief zijn voor een organisatie, omdat waardevolle tijd wordt besteed aan het zoeken naar informatie in plaats van aan kernactiviteiten. Het succes van knowledge management hangt niet alleen af van mensen, maar ook van processen en technologie. Knowledge management systems zijn ontwikkeld om processen rondom dit fenomeen te stroomlijnen. Toch is de realiteit dat veel organisaties nog steeds geconfronteerd worden met veel uitdagingen op dit gebied. Een aantal veelvoorkomende uitdagingen zijn:
- Versplinterde kennis-silo’s
Herken jij dit? Verschillende afdelingen in je organisatie hebben elk hun eigen tools en methodes om gegevens te delen (Denk aan SharePoint, Slack of Google Drive). Handig binnen teams, maar frustrerend voor een organisatie brede samenwerking. Zonder duidelijke regels voor het organiseren van documenten wordt het vinden van informatie als zoeken naar een speld in een hooiberg.
- Slecht toegankelijke informatie
Als je organisatie groeit en meer informatie verzamelt, wordt het steeds uitdagender voor medewerkers om te vinden wat ze nodig hebben. Dit wordt vooral een probleem als je kennissysteem gebaseerd is op mappenstructuren, zoals in SharePoint.
- Gebrek aan adoptie onder medewerkers
Door het gebrek aan gebruiksgemak blijven medewerkers achter in de adoptie van kennissystemen. Dit leidt tot verlies van waardevolle kennis en beperkt het vermogen van het bedrijf om snel te leren en zich aan te passen.
LLM’s to the rescue (?)
LLM’s worden ook wel generatieve modellen genoemd en zijn ontworpen om kunstmatige content te genereren op basis van meegegeven input. Ook al zijn traditionele LLM's krachtig, ze hebben beperkingen. Zo vereisen ze veel data om getraind te worden, hebben ze veel rekenkracht nodig en kunnen ze geen antwoorden geven op vragen uit onderliggende context waarop ze niet zijn ‘voorgetraind’. In de praktijk betekent dit laatste dat een algemene LLM (zoals ChatGPT) waarschijnlijk geen correct antwoord kan geven op specifieke vragen over uw bedrijfsdata. Zo’n LLM is namelijk getraind op data van het internet. Het heeft daarom alleen kennis over dat wat er op het internet aan publieke informatie te vinden is. Het heeft dan ook weinig zin om ChatGPT een vraag te stellen over uw omzet van het afgelopen jaar. Je wordt dan simpelweg doorverwezen naar je eigen financiële afdeling.
Gelukkig is er in de wereld van AI altijd een oplossing. In dit geval is dat (niet schrikken): ‘Retrieval Augmented Generation’, ofwel RAG. Even ontleden: ‘Retrieval’ staat voor ‘ophalen’, ‘Augmented’ voor ‘toevoegen’ en ‘Generation’ voor ‘het produceren van iets nieuws’. Retrieval-modellen zijn niet nieuw. Ze zijn ontworpen om relevante informatie op te halen uit een gegeven kennisbank. Ze maken vaak gebruik van semantische zoektechnieken om de meest relevante informatie te vinden en te rangschikken op basis van een zoekopdracht. Alleen missen retrieval-modellen de capaciteit om creatieve of nieuwe inhoud te genereren. RAG speelt hierop in en combineert de generatieve kracht van traditionele LLM’s met de specificiteit van retrieval-modellen. Voor jouw organisatiedata zou RAG als volgt kunnen werken:
- Op basis van een vraag over jouw organisatie haalt een retrieval-model relevante context op uit jouw eigen kennisbank
- De vraag wordt, op basis van de opgehaalde context, beantwoord door een LLM (inclusief de bron van de opgehaalde context)
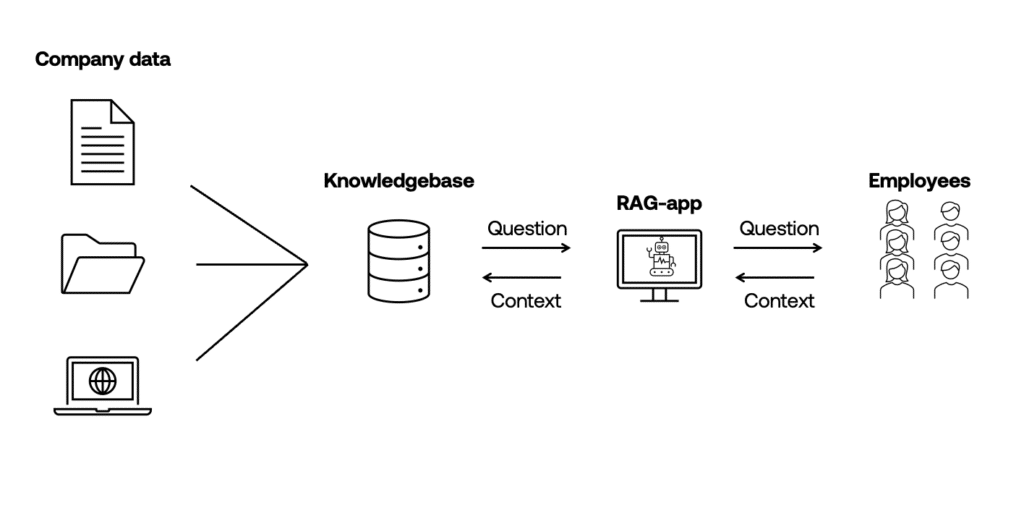
- Door het afzonderlijk koppelen van losse kennissystemen aan het RAG-model verdwijnt het probleem van versplinterde kennis-silo’s. In plaats daarvan bestaat er nu één kennisportaal waar medewerkers organisatie informatie kunnen verkrijgen.
- Het probleem van slecht toegankelijke informatie door diepe en ingewikkelde mappenstructuren verdwijnt door een versimpelde zoekmethode. Medewerkers hoeven enkel een vraag of zoekopdracht in te voeren via een interactieve interface. Hierdoor kan iedereen relevante informatie gemakkelijker krijgen, zelfs als de organisatie groeit en meer gegevens verzamelt. Dit draagt bij aan een efficiëntere informatievoorziening.
- Door een gebruiksvriendelijkere interactie met kennisbeheersystemen neemt het gebrek aan adoptie onder medewerkers af.
Conclusie
Het is een spannende tijd voor organisaties die willen profiteren van de kracht van LLM’s
De opkomst van deze nieuwe technologieën, met specifieke aandacht voor Retrieval Augmented Generation, biedt interessante kansen voor het aanpakken van uitdagingen binnen knowledge management.


