

Implementeren van MLOps
De staat van data science
Data Science is een vrij jong vakgebied en bij de meeste organisaties nog in ontwikkeling. De ene organisatie is verder dan de andere, maar in het algemeen is er een bepaalde trend te bespeuren:
Fase 1: het Lab
Het begint met een Lab: een knutselschuur voor alchemisten die met complexe algoritmen data omtoveren tot goud (althans, dat denken we).

Fase 2: in productie
Er is eindelijk een serieuze business case gevonden en een paar maanden later is er zowaar een voorspelmodel dat goed werkt. Vervolgens zijn er weliswaar nog 9 maanden aan code te herschrijven, discussies met IT en architecten (target landscape, ondersteunde tooling, OTAP, security) overheen gegaan voordat het eindelijk in productie stond, maar goed: het staat, het loopt en het werkt! Hoera!
Totdat het ineens niet meer werkt. De voorspellingen zijn niet goed, gebruikers willen wat anders, of het proces blijkt een maand geleden te zijn stuk gelopen. Maar wie gaat dit doen? Jantje, die het model ooit had gebouwd, is al lang vertrokken. Pietje kan geen chocola maken van zijn ongedocumenteerde notebooks en concludeert na een aantal reparatiepogingen dat hij het beter maar ‘from scratch’ opnieuw kan maken.
Fase 3: volwassenheid
Na door schade en schande wijzer te zijn geworden, loopt alles nu als een geoliede machine. Of het nou het ophalen, inlezen en delen van data betreft, beheren van verschillende modelexperimenten, geautomatiseerd deployen AI-gedreven API’s en apps met CI/CD, het verklaren van voorspellingen… Elk teamlid doet het met een druk op de knop en een glimlach. Juist: dit is dus science fiction.
MLOps to the rescue
Als we bovenstaand scenario iets formeler samenvatten:
- Fase 1: Experiment
- Data science opereert geïsoleerd van Business en IT
- Weinig concrete resultaten
- Geen echte waarde geleverd
- Fase 2: Live-gang
- Output wordt in productie gezet
- Maar beheer, monitoring, reproduceerbaarheid, veiligheid etc. nog niet ingericht
- Eerste waarde wordt geleverd, maar is niet duurzaam
- Fase 3: Volwassenheid
- Processen zijn effectief, efficiënt, reproduceerbaar en veilig
- Er wordt continu waarde geleverd
En daar komt MLOps om de hoek kijken: het is een manier om in fase 3 te komen.
Wat is MLOps?
“With Machine Learning Model Operationalization Management (MLOps), we want to provide an end-to-end machine learning development process to design, build and manage reproducible, testable, and evolvable ML-powered software.”
⎼ CDF sig-MLOps
“the extension of the DevOps methodology to include Machine Learning and Data Science assets as first class citizens within the DevOps ecology”
⎼ ook CDF sig-MLOps
“MLOps empowers data scientists and app developers to help bring ML models to production. MLOps enables you to track / version / audit / certify / re-use every asset in your ML lifecycle and provides orchestration services to streamline managing this lifecycle.”
⎼ Microsoft
Samengevat zou je kunnen zeggen: MLOps is DevOps maar dan voor machine learning / data science.
- Bij DS/ML/AI ontwikkelen we uiteindelijk ook software
- Dus kunnen we DevOps toepassen
- Maar DS/ML/AI omvat meer dan software ontwikkeling: denk aan datasets, modellen, trainingsresultaten
- Dus is er een uitbreiding nodig op DevOps: MLOps
Het doel van MLOps is:
Onze data science processen zijn
- Effectief
- Aantoonbaar effectief
- Efficiënt (snel)
- Reproduceerbaar
- Veilig
- Robuust/betrouwbaar
- Gemakkelijk
Ok klinkt goed, een nieuwe toverformule… Dus als je MLOps roept verdwijnen alle data science problemen op magische wijze, net zoals agile eerder alle business problemen ging oplossen?
Wat is MLOps niet?
Alles is slecht -> We introduceren MLOps -> Alles is goed.
Geen toverspreuk dus.
- Er zijn best practices, maar…
- Je moet je eigen MLOps inrichten voor je eigen processen
- afgestemd op je eigen behoeftes en prioriteiten
Maar nu even concreet
Nu even wat minder high level. Wat voor processen hebben we het over?
Data science life cycle
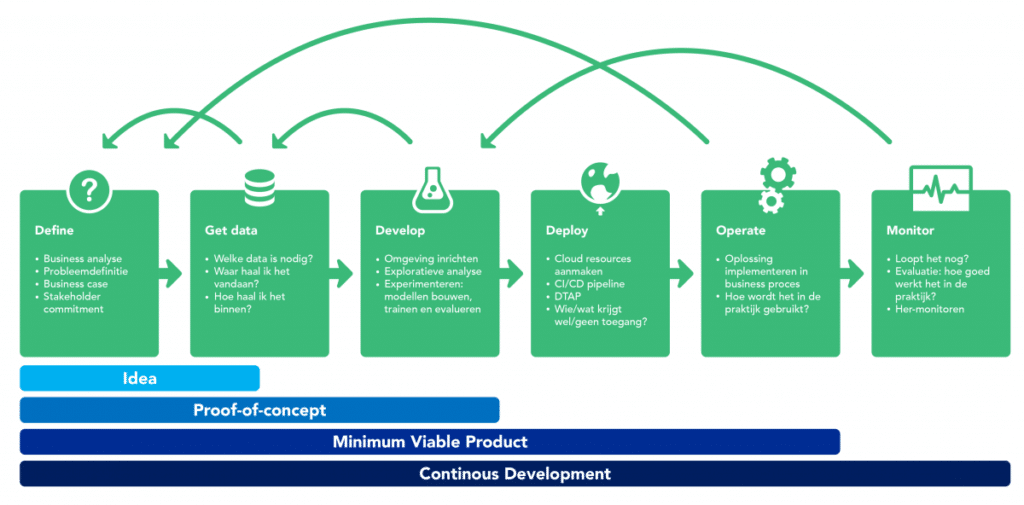
- Data version control
Hoe houden we grip op (het creëren van en modellen trainen met) verschillende datasets? - Experiment management
Hoe houden we grip op de vele modelleringsexpeirmenten (dataset + modeltype + variant + hyperparameters + score)? - Deployment & CI/CD
Hoe zetten we modellen live in api’s of apps en hoe kunnen we ze snel updaten? - Explanation
Hoe kunnen we modelvoorspellingen begrijpen en verklaren? - Monitoring
Hoe kunnen we feedbackloops inrichten de werking in de praktijk monitoren?
Praktijkvoorbeeld 1
- Pietje haalt data op met een SQL-query
- Pietje stuurt een kopie door naar Marietje
- Pietje & Marietje gaan modellen trainen op de dataset
- Pietje verbetert zijn query en gaat met een nieuwe dataset verder
- Marietje zit nog met de oude set te werken
- Marietje heeft een transformatie in een notebook gedaan en haar dataset vervangen
- Ontwikkelde modellen zijn nu afkomstig van 3 verschillende datasets
Oplossing 1: Dataset fixes netjes in de code opgenomen, zodat er een uniforme workflow ontstaat.
Oplossing 2: Data version control (voor als er echt meerdere datasets nodig zijn)
Praktijkvoorbeeld 2
Pietje’s workflow voor het trainen en evalueren van een nieuw model is als volgt:
- Dataset downloaden en in mapje plaatsen
- py draaien
- In train.py alle code runnen van model 2 behalve alle plots
- In eval.py regel aanpassen met model bestandsnaam en resultaten opslaan in nieuw bestandje
Deze werkwijze scoort slecht op reproduceerbaarheid, betrouwbaarheid en schaalbaarheid.
Oplossing: Gestandaardiseerde scripts + experiment management tool om trainingsresultaten te loggen.
Tooling
Zijn er tools voor MLOps? Zeker. Ze schieten zelfs als paddestoelen uit de grond. Sommige tools zijn breed en bieden functionaliteiten voor (vrijwel) de hele life cycle. Andere tools richten zich op een of meerdere specifieke onderdelen. Een greep uit de collectie:
- Full circle
- Data version control
- Experiment management
- …
Hoe te starten met MLOps?
Jeetje, nog meer tools… Alsof het nog niet ingewikkeld genoeg was. Moeten we daar ook al aan? Ja en nee.
Aan de ene kant: Ja, als je effectief wilt zijn moet je nou eenmaal investeren in professionalisering.
Aan de andere kant: Nee, ga niet zomaar extra tools binnenhalen met oplossingen die voor jou niet relevant zijn. Bovendien is veel op te lossen met slimmere processen en met gebruik van tools die je misschien al in huis hebt (git, Docker, template scripts).
Er is niet één juiste MLOps inrichting. De juiste inrichting is afgestemd op jouw eigen situatie: onderdelen die voor jou relevant zijn en knelpunten die bij jou spelen. De inrichting doe je niet in een keer, maar in stapjes. Pas een agile mindset toe op je MLOps inrichting:
- bepaal je prioriteiten
- los eerst één ding op, dan pas door met het volgende
- evalueren en bijsturen
Een nog paar algemene tips en uitgangspunten:
- Production mindset from the start
- Vanaf het begin ingesteld zijn op hoe het in productie gaat, dan hoef je niks om te bouwen
- Goede templates zijn het halve werk
- datascience-as-code
- Alles moet eenduidig reproduceerbaar (i.e. scriptable) zijn: modellen trainen, cloud resources aanmaken, Python-omgeving inrichten, preprocessing, deployment
- Wees pragmatisch
- Think big, but start small
- Focus op wat relevant is voor jou


